
領先一步
VMware 提供培訓和認證,助您加速進步。
瞭解更多在本系列部落格的第一部分中,我們探討了將 Spring AI 與大型語言模型整合的基礎知識。我們逐步構建了一個自定義 ChatClient,利用函式呼叫進行動態互動,並完善了提示以適應 Spring Petclinic 的用例。最終,我們擁有了一個功能齊全的 AI 助手,能夠理解和處理與我們的獸醫診所領域相關的請求。
現在,在第二部分中,我們將透過探索檢索增強生成(RAG)進一步深入,這項技術使我們能夠處理那些無法透過典型函式呼叫方法滿足的大型資料集。讓我們看看 RAG 如何將 AI 與特定領域的知識無縫整合。
雖然列出獸醫可以是一個直接的實現,但我選擇將其作為一個機會來展示檢索增強生成(RAG)的強大功能。
RAG 將大型語言模型與即時資料檢索相結合,以生成更準確和上下文相關的文字。儘管這個概念與我們之前的工作一致,但 RAG 通常強調從向量儲存中檢索資料。
向量儲存包含以嵌入形式存在的資料——捕捉資訊含義的數值表示,例如關於我們獸醫的資料。這些嵌入以高維向量的形式儲存,有助於基於語義而非傳統基於文字的搜尋進行高效的相似性搜尋。
例如,考慮以下獸醫及其專長:
Alice Brown 醫生 - 心臟病學
Bob Smith 醫生 - 牙科
Carol White 醫生 - 皮膚病學
在傳統的搜尋中,查詢“洗牙”將不會產生精確匹配。然而,透過由嵌入驅動的語義搜尋,系統會識別出“洗牙”與“牙科”相關。因此,Bob Smith 醫生將被作為最佳匹配返回,即使他的專長從未在查詢中明確提及。這說明了嵌入是如何捕捉底層含義而不是僅僅依賴精確關鍵詞的。儘管此過程的實現超出了本文的範圍,但您可以透過觀看此YouTube 影片瞭解更多資訊。
趣聞:這個例子是由 ChatGPT 自己生成的。
本質上,相似性搜尋透過識別搜尋查詢的數值與源資料最接近的數值進行操作。返回最接近的匹配項。將文字轉換為這些數值嵌入的過程也由 LLM 處理。
當處理大量資料時,使用向量儲存是最有效的。考慮到六個獸醫可以輕鬆地在一次 LLM 呼叫中處理,我旨在將數量增加到 256 個。雖然 256 個可能仍然相對較少,但它足以說明我們的過程。
在這種設定中,獸醫可以有零個、一個或兩個專長,這與 Spring Petclinic 的原始示例相呼應。為了避免手動建立所有這些模擬資料的繁瑣任務,我尋求了 ChatGPT 的幫助。它生成了一個聯合查詢,該查詢生成了 250 名獸醫,併為其中 80% 的獸醫分配了專長。
-- Create a list of first names and last names
WITH first_names AS (
SELECT 'James' AS name UNION ALL
SELECT 'Mary' UNION ALL
SELECT 'John' UNION ALL
...
),
last_names AS (
SELECT 'Smith' AS name UNION ALL
SELECT 'Johnson' UNION ALL
SELECT 'Williams' UNION ALL
...
),
random_names AS (
SELECT
first_names.name AS first_name,
last_names.name AS last_name
FROM
first_names
CROSS JOIN
last_names
ORDER BY
RAND()
LIMIT 250
)
INSERT INTO vets (first_name, last_name)
SELECT first_name, last_name FROM random_names;
-- Add specialties for 80% of the vets
WITH vet_ids AS (
SELECT id
FROM vets
ORDER BY RAND()
LIMIT 200 -- 80% of 250
),
specialties AS (
SELECT id
FROM specialties
),
random_specialties AS (
SELECT
vet_ids.id AS vet_id,
specialties.id AS specialty_id
FROM
vet_ids
CROSS JOIN
specialties
ORDER BY
RAND()
LIMIT 300 -- 2 specialties per vet on average
)
INSERT INTO vet_specialties (vet_id, specialty_id)
SELECT
vet_id,
specialty_id
FROM (
SELECT
vet_id,
specialty_id,
ROW_NUMBER() OVER (PARTITION BY vet_id ORDER BY RAND()) AS rn
FROM
random_specialties
) tmp
WHERE
rn <= 2; -- Assign at most 2 specialties per vet
-- The remaining 20% of vets will have no specialties, so no need for additional insertion commands
為了確保我的資料在每次執行時保持靜態和一致,我將 H2 資料庫中的相關表匯出為硬編碼的插入語句。然後,這些語句被新增到data.sql檔案中。
INSERT INTO vets VALUES (default, 'James', 'Carter');
INSERT INTO vets VALUES (default, 'Helen', 'Leary');
INSERT INTO vets VALUES (default, 'Linda', 'Douglas');
INSERT INTO vets VALUES (default, 'Rafael', 'Ortega');
INSERT INTO vets VALUES (default, 'Henry', 'Stevens');
INSERT INTO vets VALUES (default, 'Sharon', 'Jenkins');
INSERT INTO vets VALUES (default, 'Matthew', 'Alexander');
INSERT INTO vets VALUES (default, 'Alice', 'Anderson');
INSERT INTO vets VALUES (default, 'James', 'Rogers');
INSERT INTO vets VALUES (default, 'Lauren', 'Butler');
INSERT INTO vets VALUES (default, 'Cheryl', 'Rodriguez');
...
...
-- Total of 256 vets
-- First, let's make sure we have 5 specialties
INSERT INTO specialties (name) VALUES ('radiology');
INSERT INTO specialties (name) VALUES ('surgery');
INSERT INTO specialties (name) VALUES ('dentistry');
INSERT INTO specialties (name) VALUES ('cardiology');
INSERT INTO specialties (name) VALUES ('anesthesia');
INSERT INTO vet_specialties VALUES ('220', '2');
INSERT INTO vet_specialties VALUES ('131', '1');
INSERT INTO vet_specialties VALUES ('58', '3');
INSERT INTO vet_specialties VALUES ('43', '4');
INSERT INTO vet_specialties VALUES ('110', '3');
INSERT INTO vet_specialties VALUES ('63', '5');
INSERT INTO vet_specialties VALUES ('206', '4');
INSERT INTO vet_specialties VALUES ('29', '3');
INSERT INTO vet_specialties VALUES ('189', '3');
...
...
我們有幾種可用於向量儲存本身的選項。帶有 pgVector 擴充套件的 Postgres 可能是最受歡迎的選擇。Greenplum——一個大規模並行 Postgres 資料庫——也支援 pgVector。Spring AI 參考文件列出了當前支援的向量儲存。
對於我們簡單的用例,我選擇使用 Spring AI 提供的 SimpleVectorStore。這個類使用一個簡單的 Java ConcurrentHashMap 實現了一個向量儲存,這對於我們包含 256 名獸醫的小資料集來說綽綽有餘。這個向量儲存的配置,以及聊天記憶體的實現,都在用 @Configuration 註解的 AIBeanConfiguration 類中定義。
@Configuration
@Profile("openai")
public class AIBeanConfiguration {
@Bean
public ChatMemory chatMemory() {
return new InMemoryChatMemory();
}
@Bean
VectorStore vectorStore(EmbeddingModel embeddingModel) {
return new SimpleVectorStore(embeddingModel);
}
}
向量儲存需要在應用程式啟動時立即嵌入獸醫資料。為了實現這一點,我添加了一個 VectorStoreController bean,其中包含一個監聽 ApplicationStartedEvent 的 @EventListener。此方法會在應用程式啟動並執行後立即由 Spring 自動呼叫,確保獸醫資料在適當的時間嵌入到向量儲存中。
@EventListener
public void loadVetDataToVectorStoreOnStartup(ApplicationStartedEvent event) throws IOException {
// Fetches all Vet entites and creates a document per vet
Pageable pageable = PageRequest.of(0, Integer.MAX_VALUE);
Page<Vet> vetsPage = vetRepository.findAll(pageable);
Resource vetsAsJson = convertListToJsonResource(vetsPage.getContent());
DocumentReader reader = new JsonReader(vetsAsJson);
List<Document> documents = reader.get();
// add the documents to the vector store
this.vectorStore.add(documents);
if (vectorStore instanceof SimpleVectorStore) {
var file = File.createTempFile("vectorstore", ".json");
((SimpleVectorStore) this.vectorStore).save(file);
logger.info("vector store contents written to {}", file.getAbsolutePath());
}
logger.info("vector store loaded with {} documents", documents.size());
}
public Resource convertListToJsonResource(List<Vet> vets) {
ObjectMapper objectMapper = new ObjectMapper();
try {
// Convert List<Vet> to JSON string
String json = objectMapper.writeValueAsString(vets);
// Convert JSON string to byte array
byte[] jsonBytes = json.getBytes();
// Create a ByteArrayResource from the byte array
return new ByteArrayResource(jsonBytes);
}
catch (JsonProcessingException e) {
e.printStackTrace();
return null;
}
}
這裡有很多內容需要理解,所以讓我們來看看程式碼:
與 listOwners 類似,我們首先從資料庫中檢索所有獸醫。
Spring AI 將 Document 型別的實體嵌入到向量儲存中。Document 表示嵌入的數值資料及其原始的、人類可讀的文字資料。這種雙重表示允許我們的程式碼將嵌入向量與自然文字之間的關聯對映起來。
為了建立這些 Document 實體,我們需要將我們的 Vet 實體轉換為文字格式。Spring AI 為此提供了兩個內建讀取器:JsonReader 和 TextReader。由於我們的 Vet 實體是結構化資料,因此將它們表示為 JSON 格式是合理的。為此,我們使用輔助方法 convertListToJsonResource,該方法利用 Jackson 解析器將獸醫列表轉換為記憶體中的 JSON 資源。
接下來,我們呼叫向量儲存上的 add(documents) 方法。此方法負責透過遍歷文件列表(我們的 JSON 格式的獸醫)並嵌入每個文件,同時將其原始元資料與之關聯來嵌入資料。
雖然並非嚴格要求,但我們也生成了一個 vectorstore.json 檔案,它表示我們的 SimpleVectorStore 資料庫的狀態。此檔案允許我們觀察 Spring AI 在幕後如何解釋儲存的資料。讓我們看看生成的檔案,以瞭解 Spring AI 看到的內容。
{
"dd919c71-06bb-4777-b974-120dfee8b9f9" : {
"embedding" : [ 0.013877872, 0.03598228, 0.008212427, 0.00917901, -0.036433823, 0.03253927, -0.018089917, -0.0030867155, -0.0017038669, -0.048145704, 0.008974405, 0.017624263, 0.017539598, -4.7888185E-4, 0.013842596, -0.0028221398, 0.033414137, -0.02847539, -0.0066955267, -0.021885695, -0.0072387885, 0.01673529, -0.007386951, 0.014661016, -0.015380662, 0.016184973, 0.00787377, -0.019881975, -0.0028785826, -0.023875304, 0.024778388, -0.02357898, -0.023748307, -0.043094076, -0.029322032, ... ],
"content" : "{id=31, firstName=Samantha, lastName=Walker, new=false, specialties=[{id=2, name=surgery, new=false}]}",
"id" : "dd919c71-06bb-4777-b974-120dfee8b9f9",
"metadata" : { },
"media" : [ ]
},
"4f9aabed-c15c-43f6-9dbc-46ed9a18e176" : {
"embedding" : [ 0.01051745, 0.032714732, 0.007800559, -0.0020621764, -0.03240663, 0.025530376, 0.0037602335, -0.0023702774, -0.004978633, -0.037364256, 0.0012831709, 0.032742742, 0.005430281, 0.00847278, -0.004285406, 0.01146276, 0.03036196, -0.029941821, 0.013220336, -0.03207052, -7.518716E-4, 0.016665466, -0.0052062077, 0.010678503, 0.0026591222, 0.0091940155, ... ],
"content" : "{id=195, firstName=Shirley, lastName=Martinez, new=false, specialties=[{id=1, name=radiology, new=false}, {id=2, name=surgery, new=false}]}",
"id" : "4f9aabed-c15c-43f6-9dbc-46ed9a18e176",
"metadata" : { },
"media" : [ ]
},
"55b13970-cd55-476b-b7c9-62337855ae0a" : {
"embedding" : [ -0.0031563698, 0.03546827, 0.018778138, -0.01324492, -0.020253662, 0.027756566, 0.007182742, -0.008637386, -0.0075725033, -0.025543278, 5.850768E-4, 0.02568248, 0.0140383635, -0.017330453, 0.003935892, ... ],
"content" : "{id=19, firstName=Jacqueline, lastName=Ross, new=false, specialties=[{id=4, name=cardiology, new=false}]}",
"id" : "55b13970-cd55-476b-b7c9-62337855ae0a",
"metadata" : { },
"media" : [ ]
},
...
...
...
真酷!我們有一個 JSON 格式的 Vet,旁邊還有一組數字,雖然它們對我們來說可能沒什麼意義,但對 LLM 來說卻意義重大。這些數字代表嵌入的向量資料,模型用它來理解 Vet 實體之間的關係和語義,其方式遠超簡單的文字匹配。
如果我們在每次應用程式重啟時都執行此嵌入方法,將會導致兩個顯著的缺點:
啟動時間長:每個 Vet JSON 文件都需要透過再次呼叫 LLM 重新嵌入,從而延遲應用程式就緒。
成本增加:每次應用程式啟動時,嵌入 256 個文件將向 LLM 傳送 256 個請求,導致不必要的 LLM 信用消耗。
嵌入更適合 ETL(抽取、轉換、載入)或流處理,這些過程獨立於主 Web 應用程式執行。這些過程可以在後臺處理嵌入,而不會影響使用者體驗或產生不必要的成本。
為了簡化 Spring Petclinic 中的操作,我決定在啟動時載入預嵌入的向量儲存。這種方法可以實現即時載入並避免任何額外的 LLM 成本。這是實現該目標的方法的補充:
@EventListener
public void loadVetDataToVectorStoreOnStartup(ApplicationStartedEvent event) throws IOException {
Resource resource = new ClassPathResource("vectorstore.json");
// Check if file exists
if (resource.exists()) {
// In order to save on AI credits, use a pre-embedded database that was saved
// to disk based on the current data in the h2 data.sql file
File file = resource.getFile();
((SimpleVectorStore) this.vectorStore).load(file);
logger.info("vector store loaded from existing vectorstore.json file in the classpath");
return;
}
// Rest of the method as before
...
...
}
vectorstore.json 檔案位於 src/main/resources 下,這確保應用程式在啟動時總是載入預嵌入的向量儲存,而不是從頭開始重新嵌入資料。如果我們需要重新生成向量儲存,只需刪除現有的 vectorstore.json 檔案並重新啟動應用程式即可。一旦生成了更新的向量儲存,我們可以將新的 vectorstore.json 檔案放回 src/main/resources。這種方法提供了靈活性,同時避免了在常規重啟期間不必要的重新嵌入過程。
有了我們準備好的向量儲存,實現 listVets 函式變得簡單明瞭。該函式定義如下:
@Bean
@Description("List the veterinarians that the pet clinic has")
public Function<VetRequest, VetResponse> listVets(AIDataProvider petclinicAiProvider) {
return request -> {
try {
return petclinicAiProvider.getVets(request);
}
catch (JsonProcessingException e) {
e.printStackTrace();
return null;
}
};
}
record VetResponse(List<String> vet) {
};
record VetRequest(Vet vet) {
}
這是 AIDataProvider 中的實現:
public VetResponse getVets(VetRequest request) throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper();
String vetAsJson = objectMapper.writeValueAsString(request.vet());
SearchRequest sr = SearchRequest.from(SearchRequest.defaults()).withQuery(vetAsJson).withTopK(20);
if (request.vet() == null) {
// Provide a limit of 50 results when zero parameters are sent
sr = sr.withTopK(50);
}
List<Document> topMatches = this.vectorStore.similaritySearch(sr);
List<String> results = topMatches.stream().map(document -> document.getContent()).toList();
return new VetResponse(results);
}
讓我們回顧一下我們在這裡做了什麼:
我們從請求中的 Vet 實體開始。由於向量儲存中的記錄表示為 JSON,第一步是將 Vet 實體也轉換為 JSON。
接下來,我們建立一個 SearchRequest,它是傳遞給向量儲存的 similaritySearch 方法的引數。SearchRequest 允許我們根據特定需求微調搜尋。在這種情況下,我們主要使用預設值,除了 topK 引數,它決定返回多少結果。預設情況下,它設定為 4,但在我們的例子中,我們將其增加到 20。這使我們能夠處理更廣泛的查詢,例如“有多少獸醫專攻心臟病學?”
如果請求中未提供任何過濾器(即 Vet 實體為空),我們會將 topK 值增加到 50。這使我們能夠針對“列出診所中的獸醫”等查詢返回最多 50 位獸醫。當然,這不會是完整的列表,因為我們希望避免用過多資料淹沒 LLM。然而,我們應該沒問題,因為我們仔細調整了系統文字來管理這些情況。
When dealing with vets, if the user is unsure about the returned results,
explain that there may be additional data that was not returned.
Only if the user is asking about the total number of all vets,
answer that there are a lot and ask for some additional criteria.
For owners, pets or visits - answer the correct data.
最後一步是呼叫 similaritySearch 方法。然後,我們將每個返回結果的 getContent() 進行對映,因為這包含實際的 Vet JSON,而不是嵌入資料。
從這裡開始,一切照舊。LLM 完成函式呼叫,檢索結果,並確定如何在聊天中最佳地顯示資料。
讓我們看看它的實際效果:
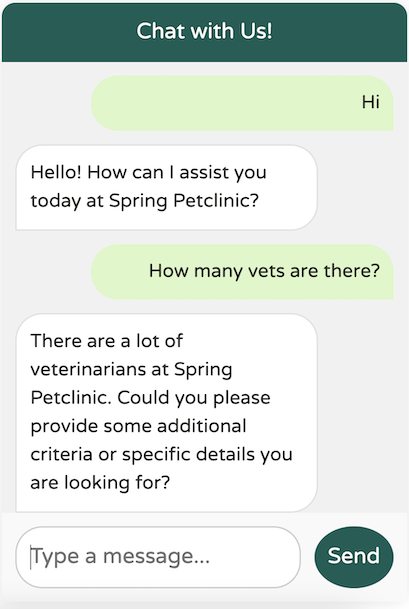
看起來我們的系統文字功能正常,避免了任何過載。現在,讓我們嘗試提供一些具體標準:
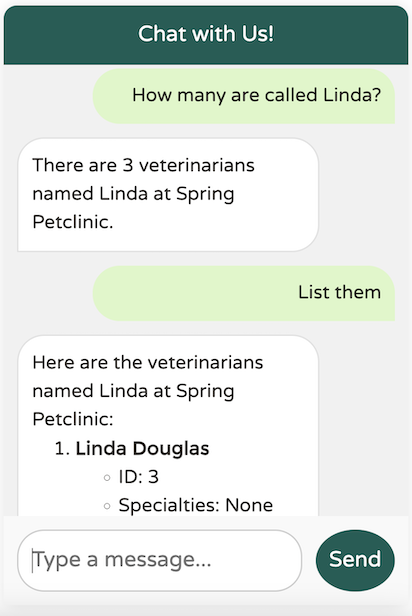
LLM 返回的資料與我們的預期完全一致。讓我們嘗試一個更廣泛的問題:

LLM 成功識別出至少 20 名專攻心臟病學的獸醫,符合我們定義的 topK 上限(20)。然而,如果對結果有任何不確定性,LLM 會指出可能還有其他可用的獸醫,正如我們的系統文字中指定的那樣。
實現聊天機器人 UI 涉及使用 Thymeleaf、JavaScript、CSS 和 SCSS 預處理器。
在審查程式碼後,我決定將聊天機器人放置在一個可以從任何選項卡訪問的位置,這使得 layout.html 成為理想的選擇。
在與 Dave Syer 博士討論 PR 時,我意識到我不應該直接修改 petclinic.css,因為 Spring Petclinic 使用 SCSS 預處理器來生成 CSS 檔案。
我承認——我主要是一名後端 Spring 開發人員,職業生涯專注於 Spring、雲架構、Kubernetes 和 Cloud Foundry。雖然我有一些 Angular 經驗,但我不是前端開發專家。我或許能想出一些東西,但它可能看起來不夠精緻。
幸運的是,我有一個很棒的結對程式設計夥伴——ChatGPT。如果您對我是如何開發 UI 程式碼感興趣,可以檢視這個ChatGPT 會話。與大型語言模型協作進行編碼練習能學到很多東西,這令人驚歎。請記住,要仔細審查建議,而不是盲目地複製貼上。
在 Spring AI 上實驗了幾個月後,我深深體會到這個專案背後的深思熟慮和努力。Spring AI 真正獨特之處在於,它允許開發人員探索 AI 的世界,而無需培訓數百名團隊成員學習 Python 等新語言。更重要的是,這種體驗突顯了一個更大的優勢:您的 AI 程式碼可以與您現有的業務邏輯共存,位於同一個程式碼庫中。您只需新增幾個額外的類,即可輕鬆地用 AI 功能增強遺留程式碼庫。避免在新的 AI 特定應用程式中從頭開始重建所有資料,這極大地提高了生產力。即使是 IDE 中現有 JPA 實體的自動程式碼完成等簡單功能也能帶來巨大的不同。
Spring AI 有潛力透過簡化 AI 功能的整合來顯著增強基於 Spring 的應用程式。它使開發人員能夠利用機器學習模型和 AI 驅動的服務,而無需深入的資料科學專業知識。透過抽象複雜的 AI 操作並將其直接嵌入到熟悉的 Spring 框架中,開發人員可以專注於快速構建智慧、資料驅動的功能。這種 AI 與 Spring 的無縫融合營造了一個創新不受技術障礙阻礙的環境,為開發更智慧、更具適應性的應用程式創造了新機遇。