
領先一步
VMware 提供培訓和認證,助您加速進步。
瞭解更多本文是部落格系列的一部分,該系列探討了基於Java Functions的全新重新設計的Spring Cloud Stream應用程式。在本篇中,我們將深入瞭解檔案供應商及其Spring Cloud Stream檔案源對應部分。我們還將看到MongoDB消費者及其相應的Spring Cloud Stream sink。最後,我們將演示如何將檔案源和MongoDB sink在Spring Cloud Data Flow上作為管道進行編排。
以下是本部落格系列的所有先前部分。
檔案攝取和從檔案讀取資料是一個經典的企業用例。幾十年來,許多企業一直依賴不同級別的檔案設施來執行任務關鍵型系統。數太位元組的資料透過網際網路和企業內網以檔案的形式傳輸。例如,想象一個銀行資料中心,它每秒從所有分支機構、ATM和POS交易中接收資料檔案,然後需要處理這些資料並將其放入其他系統。這只是一個領域,但在成千上萬的例子中,檔案處理是許多業務的關鍵路徑。有許多遺留系統,其中編寫了許多自定義應用程式,每個應用程式都採用自己的方式來處理這些用例。Spring Integration多年來一直提供檔案支援作為通道介面卡。這些元件可以實現為函式,在從檔案讀取的情況下,我們可以提供一個通用的Supplier函式,該函式可重用並注入到終端使用者應用程式中。在以下部分中,我們將看到有關此功能抽象及其各種使用場景的更多詳細資訊。
檔案供應商是一個實現為java.util.function.Supplier bean的元件,當被呼叫時,它將提供給定目錄中檔案的內容。檔案供應商具有以下簽名。
Supplier<Flux<Message<?>>>
供應商的使用者可以訂閱返回的Flux<Message<?>,它是目錄中訊息流或檔案物件本身。
為了呼叫檔案供應商,我們需要指定一個目錄來輪詢檔案。目錄資訊是必需的,並且必須透過配置屬性file.supplier.directory提供。預設情況下,供應商將以byte[]的形式生成資料,但它還透過配置屬性file.consumer.mode支援兩種額外的檔案消費模式。支援的附加值是lines和ref。檔案消費模式lines將一次消費一行檔案內容。這對於讀取CSV檔案和其他結構化文字資料等文字檔案很有用。ref模式將提供實際的File物件。預設情況下,檔案供應商還會阻止讀取它之前已經讀取過的相同檔案。這透過屬性file.supplier.preventDuplicates進行控制。
檔案供應商是一個可重用的Spring bean,我們可以將其注入到終端使用者的自定義應用程式中。一旦注入,它可以直接呼叫並與自定義資料處理相結合。這是一個例子。
@Autowired
Supplier<Flux<Message<?>>> fileSupplier;
public void consumeDataAndSendEmail() {
Flux<Message<?> data = fileSupplier.get();
messageFlux.subscribe(t -> {
if (t == something)
//send the email here.
}
}
}
在上面的虛擬碼中,我們正在注入檔案供應商bean,然後使用它來呼叫其get方法以獲取Flux。然後我們訂閱該Flux,並且每次透過Flux接收到任何資料時,都應用一些過濾,並根據該資料採取行動。這只是一個簡單的示例,旨在演示如何重用檔案供應商。當您在實際應用程式中嘗試此操作時,您可能需要在實現中進行更多調整,例如在進行條件檢查之前將接收到的資料的預設資料型別從byte[]轉換為其他型別,或者將預設檔案讀取模式從content更改為lines等。
當檔案供應商與Spring Cloud Stream結合使用時,它變得更加強大,可以成為檔案源。正如我們在之前的部落格中看到的,此供應商已經預打包了Kafka和RabbitMQ繫結器在Spring Cloud Stream中,使它們成為可作為Spring Boot應用程式執行的uber jars。讓我們看看如何獲取這個uber jar並作為獨立應用程式執行。
作為第一步,繼續並獲取帶有 Apache Kafa 變體的此檔案源。
wget https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/file-source-kafka/3.0.0-SNAPSHOT/file-source-kafka-3.0.0-SNAPSHOT.jar
確保Kafka在預設埠執行。
現在是時候獨立執行檔案源了。
java -jar file-source-kafka-3.0.0-SNAPSHOT.jar --file.supplier.directory=/tmp/data-files --file.consumer.mode=lines --spring.cloud.stream.bindings.output.destination=file-data
預設情況下,Spring Cloud Stream 期望輸出繫結為 fileSupplier-out-0(因為 fileSupplier 是供應商 bean 名稱)。然而,當生成這些應用程式時,此輸出繫結被覆蓋為 output。這樣做是為了滿足在 Spring Cloud Data Flow 上執行此源應用程式時的一些要求。
我們還要求應用程式讀取落在/tmp/data-files目錄中的檔案,並將其作為一次一行(使用lines模式)進行消費。
觀看 Kafka 主題 `file-data`。使用 kafkacat 工具,你可以這樣做
kafkacat -b localhost:9092 -t file-data
現在,將一些檔案放入/tmp/data-files目錄。您將看到資料到達file-data Kafka主題,檔案中每一行代表一個Kafka記錄。
如果您想將檔案限制為特定模式,可以使用屬性file.supplier.filenamePattern使用簡單的命名模式,或者使用屬性file.supplier.filenameRegex使用更復雜的基於正則表示式的模式。
正如我們在此部落格系列的第二部分中看到的,所有開箱即用的Spring Cloud Stream源應用程式都已自動配置了幾個開箱即用的通用處理器。您可以將這些處理器作為檔案源的一部分啟用。這裡有一個示例,我們執行檔案源並接收資料,然後轉換消費的資料,再將其傳送到中介軟體上的目標。
java -jar file-source-kafka-3.0.0-SNAPSHOT.jar --file.supplier.directory=/tmp/data-files --file.consumer.mode=lines --spring.cloud.stream.bindings.output.destination=file-data --spring.cloud.function.definition=fileSupplier|spelFunction --spel.function.expression=payload.toUpperCase()
透過為spring.cloud.function.definition屬性提供值fileSupplier|spelFunction,我們激活了與檔案供應商組合的spel函式。然後我們提供了一個SpEL表示式,我們想用它來使用spel.function.expression轉換資料。
還有其他幾個功能可以這樣組合。更多詳情請參閱此處。
MongoDB消費者提供了一個函式,允許使用者從外部系統接收資料,然後將該資料寫入MongoDB。我們可以在自定義應用程式中直接使用消費者bean將資料插入到MongoDB集合中。以下是MongoDB消費者bean的型別簽名。
Consumer<Message<?>> mongodbConsumer
一旦注入到自定義應用程式中,使用者可以直接呼叫消費者的accept方法,並提供一個Message<?>物件以將其有效載荷傳送到MongoDB集合。
使用MongoDB消費者時,集合是一個必需屬性,必須透過mongodb.consumer.collection進行配置。
與檔案源的情況一樣,Spring Cloud Stream開箱即用的應用程式已經使用MongoDB消費者提供了MongoDB sink。該sink適用於Kafka和RabbitMQ繫結器變體。當用作Spring Cloud Stream sink時,MongoDB消費者會自動配置為接受來自相應中介軟體系統的資料,例如,來自Kafka主題或RabbitMQ交換機的資料。
讓我們花幾分鐘驗證我們可以獨立執行MongoDB sink。
在終端視窗中執行以下命令。
docker run -d --name my-mongo \
-e MONGO_INITDB_ROOT_USERNAME=mongoadmin \
-e MONGO_INITDB_ROOT_PASSWORD=secret \
-p 27017:27017 \
mongo
docker exec -it my-mongo /bin/sh
這將使我們進入正在執行的 docker 容器的 shell 會話。在 shell 中呼叫以下命令。
# mongo
> use admin
> db.auth('mongoadmin','secret')
1
> db.createCollection('test_collection’')
{ "ok" : 1 }>
現在我們已經設定好MongoDB,讓我們獨立執行sink。
wget https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/mongodb-sink-kafka/3.0.0-SNAPSHOT/mongodb-sink-kafka-3.0.0-SNAPSHOT.jar
java -jar mongodb-sink-kafka-3.0.0-SNAPSHOT.jar --mongodb.consumer.collection=test_collection --spring.data.mongodb.username=mongoadmin --spring.data.mongodb.password=secret --spring.data.mongodb.database=admin --spring.cloud.stream.bindings.input.destination=test-data-mongo
將一些JSON資料插入Kafka主題test-data-mongo。例如,您可以使用Kafka附帶的控制檯生產者指令碼,如下所示。
/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test-data-mongo
然後像這樣生成資料
{"hello":"mongo"}
轉到上面我們在 Docker shell 中啟動的終端上的 MongoDB CLI。
db.test_collection.find()
透過 Kafka 主題輸入的資料應作為輸出顯示。
獨立執行檔案源和MongoDB很好,但是Spring Cloud Data Flow使其非常容易將它們作為管道執行。基本上,我們想要編排一個相當於檔案源 | 過濾器 | MongoDB的流。
本系列中的一篇部落格專門介紹瞭如何執行Spring Cloud Data Flow並部署應用程式作為流的所有細節。如果您不熟悉執行Spring Cloud Data Flow,請回顧該部落格。下面,我們簡要提供了設定Spring Cloud Data Flow所涉及的步驟。
首先,我們需要獲取用於執行Spring Cloud Data Flow的docker-compose檔案。
wget -O docker-compose.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.6.0/spring-cloud-dataflow-server/docker-compose.yml
另外,獲取用於執行MongoDB的此附加docker-compose檔案。
wget -O mongodb.yml https://raw.githubusercontent.com/spring-cloud/stream-applications/gh-pages/files/mongodb.yml
我們需要設定一些環境變數才能正確執行 Spring Cloud Data Flow。
export DATAFLOW_VERSION=2.6.0
export SKIPPER_VERSION=2.5.0
export STREAM_APPS_URI=https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/stream-applications-descriptor/2020.0.0-SNAPSHOT/stream-applications-descriptor-2020.0.0-SNAPSHOT.stream-apps-kafka-maven
現在我們萬事俱備,是時候啟動 Spring Cloud Data Flow 和所有其他輔助元件了。
docker-compose -f docker-compose.yml -f mongo.yml up
SCDF 啟動並執行後,請訪問 https://:9393/dashboard。然後轉到左側的 Streams 並選擇 Create Stream。從源應用程式中選擇 File,從處理器中選擇 Filter,從 sink 應用程式中選擇 MongoDB。單擊選項並選擇以下屬性。這是選擇所有屬性後應該顯示的樣子。
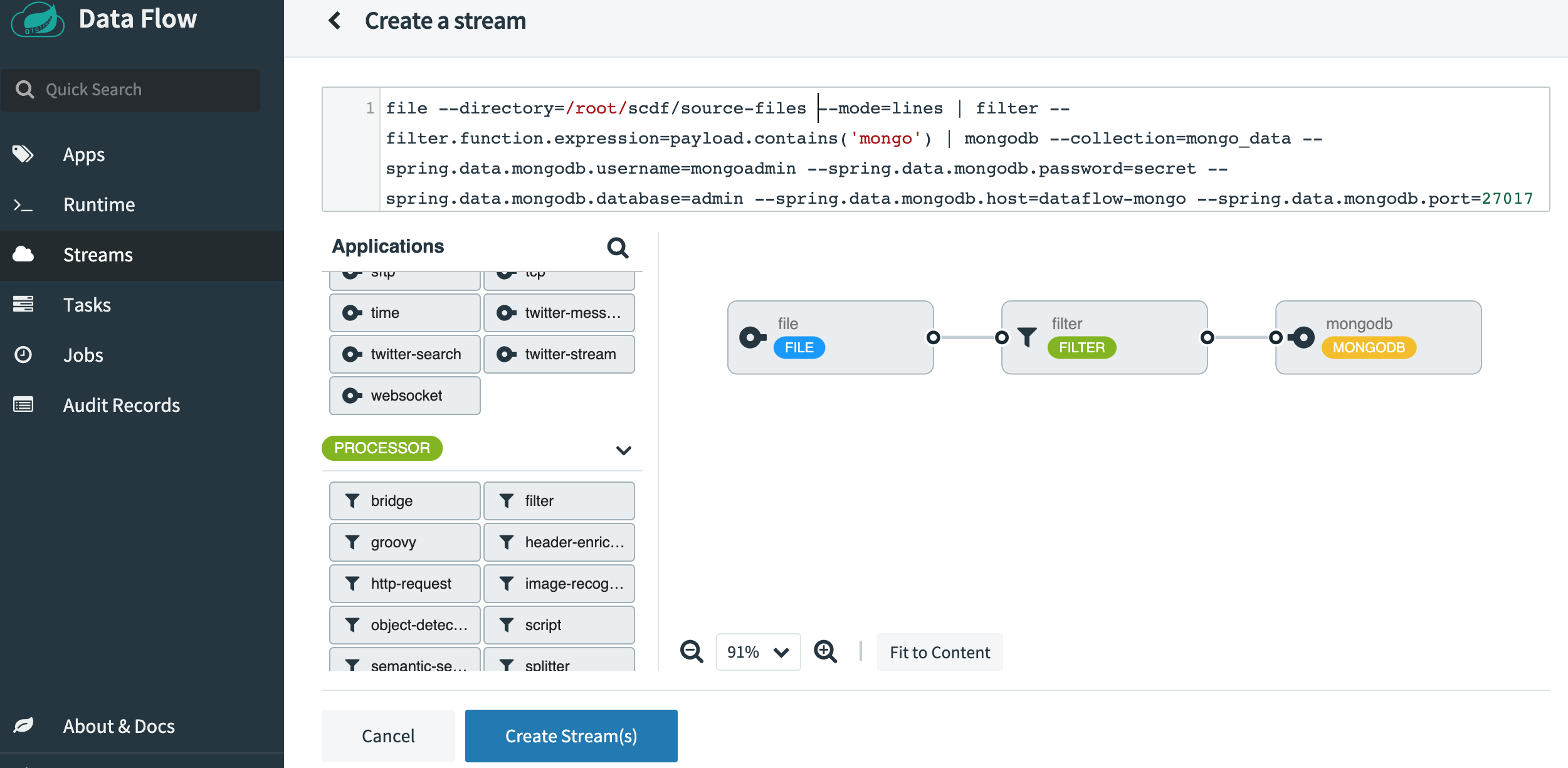
將流命名為file-source-filter-mongo,然後點選Create the Stream。建立後,點選“Deploy the Stream”。接受所有預設選項,然後點選螢幕底部的“Deploy Stream”。
流部署完成後,在呼叫 Spring Cloud Data Flow docker-compose 指令碼的同一目錄中建立一個名為 source-files 的目錄。此目錄已由執行 Spring Cloud Data Flow 元件(Skipper)之一的 docker 容器掛載並被容器看到。確保此 source-files 目錄具有正確的訪問級別,尤其是在 docker 容器將以 root 使用者身份執行應用程式而您很可能以非 root 使用者身份在本地機器上執行時。在 UI 上檢視檔案源應用程式的日誌,以查詢任何許可權錯誤。如果看到任何錯誤,請解決這些問題。
使用 mongo CLI 工具準備一個新的終端會話。
docker exec -it dataflow-mongo /bin/sh
# mongo
> use admin
> db.auth(‘mongoadmin’,'secret')
1
> db.createCollection(‘mongo_data’')
{ "ok" : 1 }>
在source-files目錄中放置一些檔案,內容如下。
{"non-sql":"mongo"}
{"sql":"mysql"}
{"document":"mongo"}
{"log":"kafka"}
{"sink":"mongo"}
轉到mongo命令列終端會話。
db.mongo_data.find()
您會看到我們新增到管道中的過濾元件過濾掉了檔案中所有不包含“mongo”一詞的條目。您應該會看到類似於以下內容的輸出。
{ "_id" : ObjectId("5f4551c470e0373080fcd0b8"), "non-sql" : "mongo" }
{ "_id" : ObjectId("5f4551c470e0373080fcd0b2"), "sink" : "mongo" }
{ "_id" : ObjectId("5f4551c470e0373080fcd0b5"), "document" : "mongo" }
在這篇部落格中,我們對檔案供應商及其Spring Cloud Stream源對應部分進行了旋風式的考察。我們還了解了MongoDB消費者和相應的Spring Cloud Stream sink應用程式。我們研究瞭如何將功能元件注入自定義應用程式。之後,我們看到了如何獨立執行檔案源和MongoDB sink的Spring Cloud Stream應用程式。最後,我們深入研究了Spring Cloud Data Flow,並編排了一個從檔案源到MongoDB sink的管道,並在途中過濾掉了一些資料。
這個部落格系列將會繼續。在接下來的幾周裡,我們將探討更多類似於我們在這篇部落格中描述的場景,但會使用不同的函式和應用程式。