
{kind=link}
領先一步
VMware 提供培訓和認證,助您加速進步。
瞭解更多到目前為止,在本系列中,我們已經介紹了基於 Java 函式的新流應用程式以及函式組合。我們還提供瞭如何從供應商構建源以及從消費者構建接收器的詳細示例。在這裡,我們繼續接下來的幾個案例研究中的第一個。每個案例研究都演示瞭如何在各種場景中使用一個或多個可用的預打包 Spring Boot 流應用程式來構建資料流管道。
今天我們將展示兩個最常用的應用程式:HTTP 源和JDBC 接收器。我們將使用它們構建一個簡單的服務,該服務接受 HTTP POST 請求並將內容儲存到資料庫表中。我們將首先將它們作為獨立的Spring Cloud Stream應用程式執行,然後展示如何使用Spring Cloud Data Flow編排相同的管道。本文以分步教程的形式呈現,我們鼓勵您在閱讀時遵循這些步驟。
這個簡單的流應用程式由兩個透過訊息代理進行通訊的遠端程序組成。預打包的流應用程式可以開箱即用地與 Apache Kafka 或 RabbitMQ 配合使用。這裡我們將使用 Apache Kafka。JDBC 接收器將資料插入資料庫。在本例中,我們將使用 MySQL。
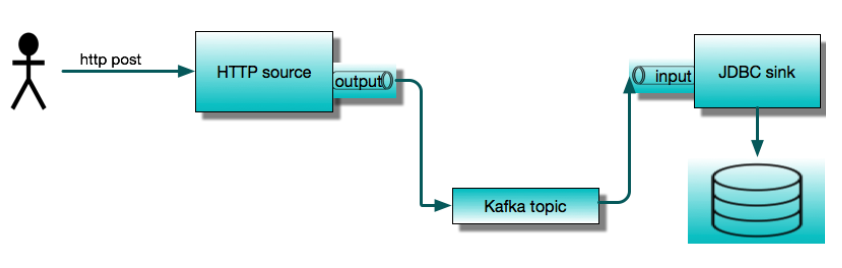
假設我們從頭開始,開發環境中沒有 Kafka 或 MySQL。為了執行這個示例,我們將使用 Docker。因此,我們需要在本地機器上執行 Docker。稍後我們將使用 Spring Cloud Data Flow,所以我們將利用 Data Flow 的 docker-compose 安裝。這是開始使用 Data Flow 的最簡單方法。它會啟動多個容器,包括 MySQL 和 Kafka。為了使這些後端服務可用於獨立應用程式,我們需要調整標準安裝以釋出埠,並更改 Kafka 的廣告主機名。
注意
我已經在 Mac OS 上使用此設定執行,並期望類似的設定也能在 Windows 上執行。如果您遇到問題或有任何有用的提示,請在評論區留言。
首先,讓我們建立一個名為 http-jdbc-demo 的目錄,並將 docker-compose.yml 從 github 下載到該目錄。
wget -O docker-compose.yml https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.6.0/spring-cloud-dataflow-server/docker-compose.yml
或
curl https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.6.0/spring-cloud-dataflow-server/docker-compose.yml -o docker-compose.yml
為了能夠從本地主機連線到 Kafka 和 MySQL,我們將下載另一個 YAML 檔案來覆蓋我們的自定義配置。
wget -O shared-kafka-mysql.yml https://raw.githubusercontent.com/spring-cloud/stream-applications/gh-pages/files/shared-kafka-mysql.yml
接下來,我們需要獲取本地機器的區域網 IP 地址。在 Mac 上,您可以透過以下幾種方式之一完成此操作,例如
dig +short $(hostname)
或
ping $(hostname)
區域網 IP 地址對 docker 容器也是可訪問的,而容器內部的 localhost 或 127.0.0.1 指的是自身。我們需要將環境變數 KAFKA_ADVERTISED_HOST_NAME 設定為這個值。我們還需要設定其他幾個環境變數
export KAFKA_ADVERTISED_HOST_NAME=$(dig +short $(hostname))
export DATAFLOW_VERSION=2.6.0
export SKIPPER_VERSION=2.5.0
並註冊 Data Flow 中的最新流應用程式
export STREAM_APPS_URI=https://repo.spring.io/libs-snapshot-local/org/springframework/cloud/stream/app/stream-applications-descriptor/2020.0.0-SNAPSHOT/stream-applications-descriptor-2020.0.0-SNAPSHOT.stream-apps-kafka-maven
現在,從我們的專案目錄中,我們可以啟動 Data Flow 叢集。
docker-compose -f docker-compose.yml -f shared-kafka-mysql.yml up
這將顯示大量日誌訊息並持續執行,直到您終止它(例如,Ctrl-C),這將停止所有容器。保持此終端開啟。
開啟一個新的終端並輸入
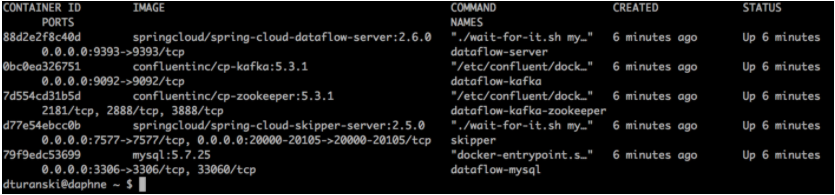
docker ps
這將列出 Data Flow 叢集中正在執行的容器。我們稍後會檢視 Data Flow。此時,請確保 dataflow-kafka 容器在 PORTS 下顯示 0.0.0.0:9092→9092/tcp,並且 dataflow-mysql 類似地顯示 0.0.0.0:3306→3306/tcp。
我們可以將 JDBC sink 應用程式配置為自動初始化資料庫,但為了簡單起見,我們將手動建立它。我們可以使用任何 JDBC 資料庫工具或透過在 dataflow-mysql 容器內執行 mysql 來完成此操作。
docker exec -it dataflow-mysql mysql -uroot -p
系統將提示您輸入密碼。資料庫憑據已在 docker-compose.yml 中配置。如果您不想在那裡查詢,使用者名稱是 root,密碼是 rootpw。
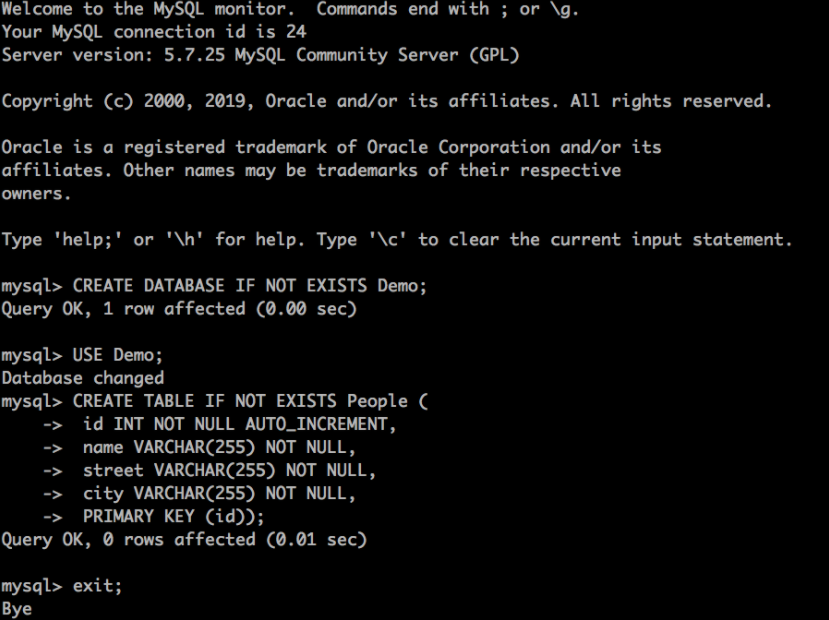
輸入以下命令——您應該能夠複製並貼上整個內容——以建立資料庫和表。
CREATE DATABASE IF NOT EXISTS Demo;
USE Demo;
CREATE TABLE IF NOT EXISTS People (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
street VARCHAR(255) NOT NULL,
city VARCHAR(255) NOT NULL,
PRIMARY KEY (id));
輸入 exit; 退出。
此時,我們準備執行 HTTP 源和 JDBC 接收器。Spring Boot 可執行 JAR 已釋出到 Spring Maven 倉庫。我們需要使用 Kafka 繫結器構建的 JAR。
wget https://repo.spring.io/snapshot/org/springframework/cloud/stream/app/http-source-kafka/3.0.0-SNAPSHOT/http-source-kafka-3.0.0-SNAPSHOT.jar
wget https://repo.spring.io/snapshot/org/springframework/cloud/stream/app/jdbc-sink-kafka/3.0.0-SNAPSHOT/jdbc-sink-kafka-3.0.0-SNAPSHOT.jar
我們將在單獨的終端會話中執行這些。我們需要配置這些應用程式以使用相同的 Kafka 主題,我們稱之為 jdbc-demo-topic。Spring Cloud Stream Kafka 繫結器將自動建立此主題。我們還需要配置 JDBC 接收器以連線到我們的資料庫並將資料對映到我們建立的表。我們將釋出如下所示的 JSON
{
“name”:”My Name”,
“address”: {
“street”:”My Street”,
“city”: “My City”
}
}
我們要將這些值插入到 Demo 資料庫的 People 表中,插入到 name、street 和 city 列中。
開啟我們下載 jar 的新終端會話並執行
java -jar jdbc-sink-kafka-3.0.0-SNAPSHOT.jar --spring.datasource.url=jdbc:mariadb://:3306/Demo --spring.datasource.username=root --spring.datasource.password=rootpw --jdbc.consumer.table-name=People --jdbc.consumer.columns=name,city:address.city,street:address.street --spring.cloud.stream.bindings.input.destination=jdbc-demo-topic
請注意用於將欄位對映到列的 jdbc.consumer.columns 語法。
開啟我們下載 jar 的新終端會話並執行
java -jar http-source-kafka-3.0.0-SNAPSHOT.jar --server.port=9000 --spring.cloud.stream.bindings.output.destination=jdbc-demo-topic
這裡我們將源的 HTTP 埠設定為 9000(預設為 8080)。此外,源的輸出目的地與接收器的輸入目的地匹配非常重要。
接下來,我們需要向 https://:9000 釋出一些資料。
curl https://:9000 -H'Content-Type:application/json' -d '{"name":"My Name","address":{"street":"My Street","city":"My City"}}}
再次,找到一個開放的終端會話並
docker exec -it dataflow-mysql mysql -uroot -p
使用 rootpw 登入並查詢表
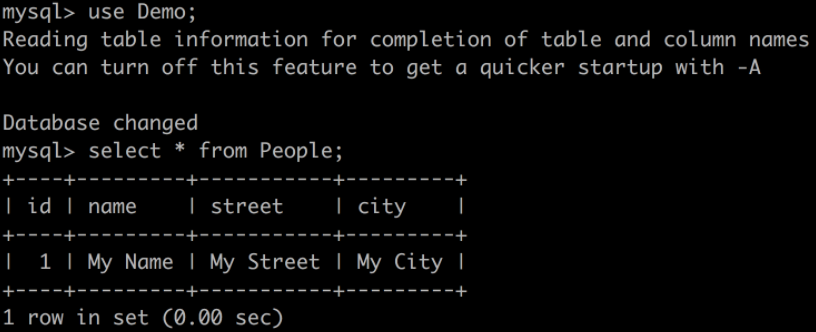
如果你看到這個,恭喜你!獨立的 Spring Cloud Stream 應用程式按預期工作。我們現在可以終止我們的獨立應用程式 (Ctrl-C)。讓 docker-compose 程序保持執行,以便我們可以檢視 Data Flow。
正如我們所看到的,即使我們不需要編寫任何程式碼,在“裸機”上執行這些應用程式也需要很多手動步驟。這些步驟包括
自定義 docker-compose 配置,或者在本地機器上安裝 kafka 和 mysql
使用 Maven URL 下載所需版本的流應用程式(我們碰巧知道這裡要使用哪些)
確保 Spring Cloud Stream 目標繫結已正確配置,以便應用程式可以通訊
查詢並閱讀 文件 以獲取配置屬性(我們已經完成了這些以準備此示例)並正確設定它們。
管理多個終端會話
在接下來的部分中,我們將看到使用 Spring Cloud Data Flow 可以消除所有這些步驟,並提供更豐富的整體開發體驗。
要開始,請開啟 Data Flow Dashboard,地址為 https://:9393/dashboard。這將帶您進入應用程式檢視,您可以在其中看到已註冊的預打包應用程式。我們之前執行的 docker-compose 命令執行了此步驟,它使用我們提供的 URL 獲取流應用程式的最新快照版本,包括我們剛剛執行的相同 jar 檔案。
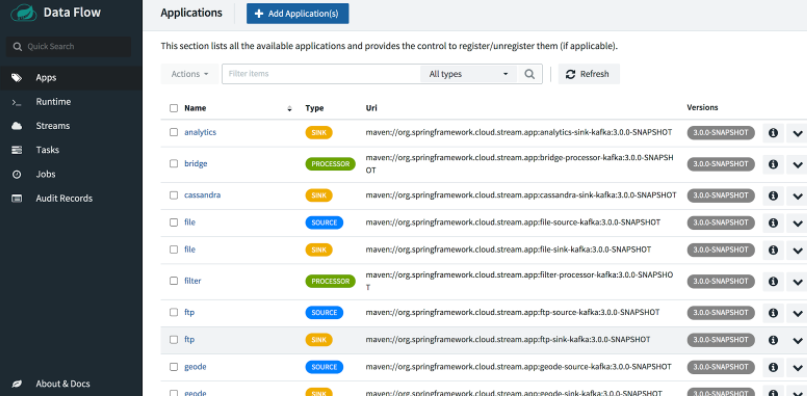
在控制面板中,從左側選單中選擇 Streams,然後單擊 Create Streams 以開啟圖形化流編輯器。
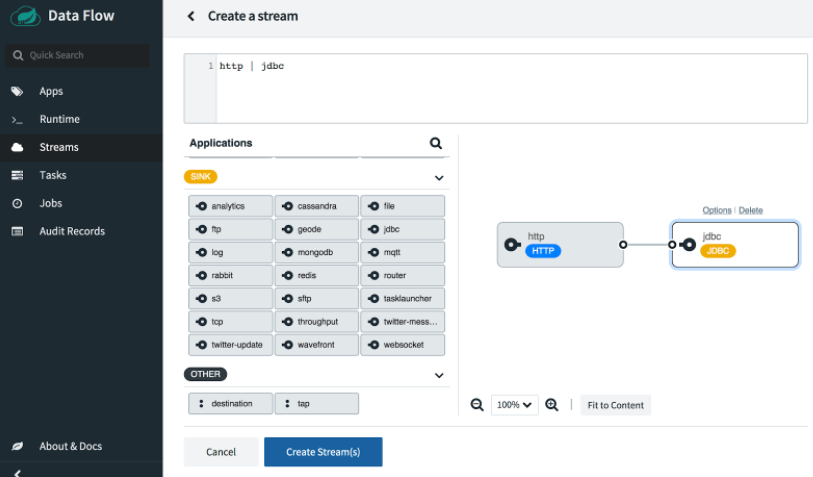
將 http 源和 jdbc 接收器拖放到編輯器窗格中,然後使用滑鼠連線兩個控制代碼。或者,您可以直接在頂部的文字框中鍵入 Data Flow 流定義 DSL:http | jdbc。
接下來我們需要配置應用程式。如果您點選任何一個應用程式,您將看到一個 Options 連結。開啟 JDBC sink 的選項視窗。您將看到所有可用的配置屬性以及簡短描述。以下螢幕截圖顯示了部分檢視;我們需要滾動才能看到其餘部分。
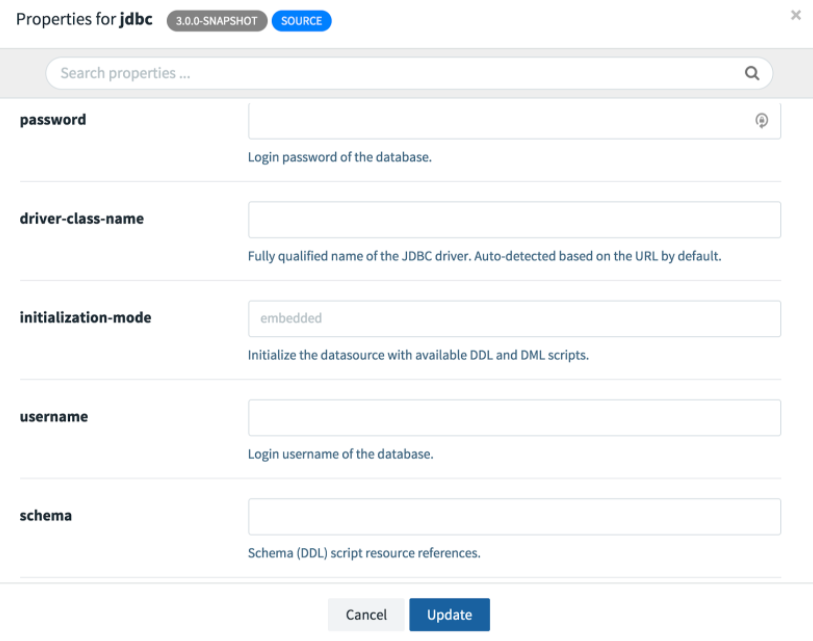
與之前一樣,我們需要提供 URL、使用者名稱、密碼、表和列。在這裡,我們需要將 JDBC URL 更改為 jdbc:mariadb://mysql:3306/Demo,因為主機名 mysql 對應於 docker-compose.yml 中定義的 mysql 服務名稱。此外,我們將 http 埠設定為 20000,因為它在已配置的已釋出埠範圍內。有關更多詳細資訊,請參閱 skipper-server 配置。
讓我們看看自動生成的流定義 DSL
http --port=20000 | jdbc --password=rootpw --username=root --url=jdbc:mariadb://mysql:3306/Demo --columns=name,city:address.city,street:address.street --table-name=People
此 DSL 可用於指令碼或 Data Flow 客戶端應用程式以自動化流建立。我們的配置已完成,但 Spring Cloud Stream 目標繫結在哪裡?我們不需要它們,因為 Data Flow 為我們處理了連線。
選擇 Create Stream 按鈕並將流命名為 http-jdbc。
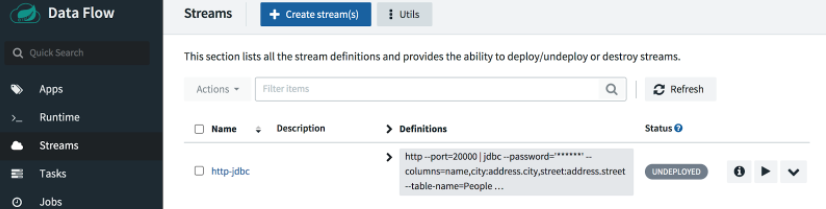
要部署流,請單擊播放按鈕

接受預設部署屬性,然後單擊頁面底部的 Deploy stream。
根據需要點選 Refresh 按鈕。大約一分鐘後,您應該會看到我們的流已部署。
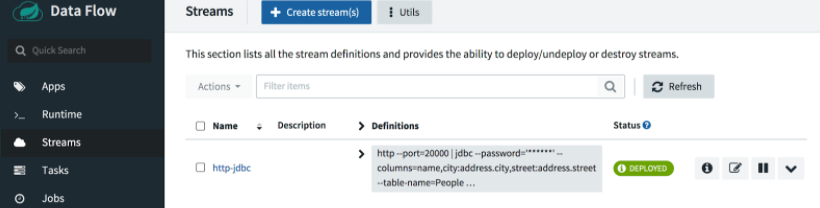
這裡我們將向埠 20000 釋出一些不同的值
curl https://:20000 -H'Content-Type:application/json' -d '{"name":"Your Name","address":{"street":"Your Street","city":"Your City"}}}'
當我們再次執行查詢時,我們應該會看到表中添加了一行新資料。
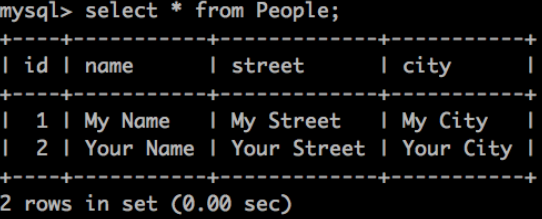
幹得好!
敏銳的讀者會注意到,即使平臺本身在容器中執行,也沒有為部署的應用程式建立 Docker 容器。在 Data Flow 架構中,Skipper 伺服器負責部署流應用程式。在本地配置中,Skipper 使用本地部署器在其 localhost 上執行 jar 檔案,就像我們執行獨立應用程式時一樣。為了證明這一點,我們可以在 Skipper 容器中執行 ps
docker exec -it skipper ps -ef

要檢視控制檯日誌,請使用 stdout 路徑
docker exec -it skipper more /tmp/1596916545104/http-jdbc.jdbc-v4/stdout_0.log
tail -f 命令也適用。
如果部署成功,應用程式日誌也可以從 UI 中檢視。
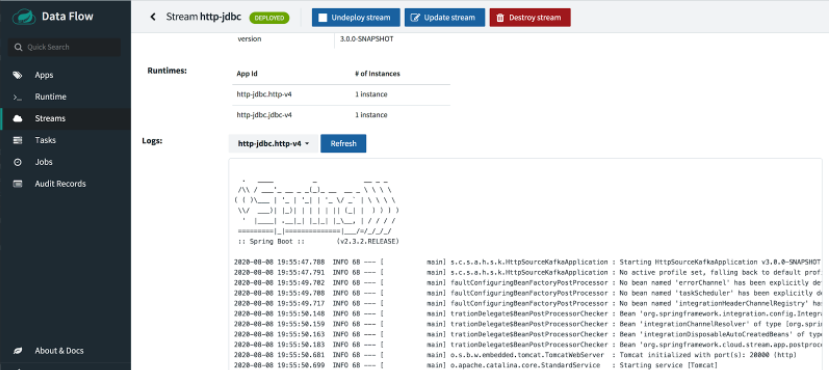
但如果部署失敗,我們可能需要深入研究以解決問題。
注意
本地 Data Flow 安裝適用於本地開發和探索,但我們不建議將其用於生產環境。生產級別的 Spring Cloud Data Flow OSS 以及商業許可產品可用於 Kubernetes 和 Cloud Foundry。
我們剛剛仔細研究瞭如何使用預打包的 Spring Cloud Stream 應用程式構建一個簡單的資料流管道,以將透過 HTTP 釋出的 JSON 內容儲存到關係資料庫中。我們使用 Docker 和 docker-compose 安裝了一個本地環境,然後我們部署了源和接收器應用程式,首先在“裸機”上,然後使用 Spring Cloud Data Flow。希望我們學到了一些關於使用 Spring Cloud Stream、Data Flow、Docker 容器、HTTP 源和 JDBC 接收器有趣的知識。
在接下來的幾周,我們將展示更多 Spring Cloud Stream 和 Spring Cloud Data Flow 的案例研究,每個案例都將探索不同的流應用程式和功能。