
領先一步
VMware 提供培訓和認證,助您加速進步。
瞭解更多作為一名探索生成式 AI 世界的 Java 開發者,你可能已經瞭解一些聲稱能讓 AI 整合變得簡單的框架。我相信 Spring AI 脫穎而出,成為自然而然的選擇,特別是對於已經在 Spring 生態系統中工作的開發者而言。Spring AI 建立在與 Spring Boot 和 Spring Data 相同的基礎之上,它使 為你的應用程式新增 AI 功能 變得無縫且直觀,而無需你學習一套全新的正規化。
Spring AI 最顯著的優勢之一是它與 Spring 生態系統的深度整合。如果你已經熟悉 Spring Boot 應用程式的開發,Spring AI 將會讓你覺得它只是你已有知識的擴充套件。驅動 Spring Data 的相同概念,例如依賴注入、註解和清晰的抽象,也同樣適用於 Spring AI。這種一致性意味著你可以直接投入到 AI 開發中,而無需重新思考如何開發你的應用程式。
與某些工具不同,Spring AI 不需要複雜的配置或工作流設定即可開始使用。它與你現有的程式碼庫完美契合,允許你重用現有的 Bean、服務和儲存庫。Spring AI 不是簡單地附加一個外部 AI 平臺,而是直接與你已構建的業務邏輯和企業服務整合,充分利用你在 Spring 生態系統中的投入。
Spring AI 專注於簡化企業級應用的 AI 操作。它非常適合需要向其業務應用新增簡單 AI 功能(如文字生成、嵌入和函式呼叫)的開發人員。Spring AI 的美妙之處在於其簡潔性:你可以在不承擔管理複雜工作流或協調多步驟流程的開銷的情況下,獲得生成式 AI 的強大功能。對於大多數企業用例來說,AI 的作用是增強功能而不是驅動整個工作流,Spring AI 正好提供了所需的一切。
Spring AI 的另一個關鍵優勢是其與向量儲存的整合。無論你使用帶有 pgVector 的 Postgres、Redis,還是任何其他支援向量的資料庫,Spring AI 都擴充套件了 Spring 眾所周知的處理向量嵌入和其他 AI 驅動的資料儲存需求的能力。
Spring AI 讓在不同向量儲存實現之間切換變得異常容易。使用 Spring 開發者熟悉的相同依賴注入模式,你只需更改 Spring Boot Starter 依賴項即可替換一個向量儲存,而無需觸及核心應用程式邏輯。這種靈活性對於構建需要可擴充套件、高效儲存和檢索嵌入或其他 AI 生成資料的 AI 增強應用程式的開發者來說是一個顯著優勢。
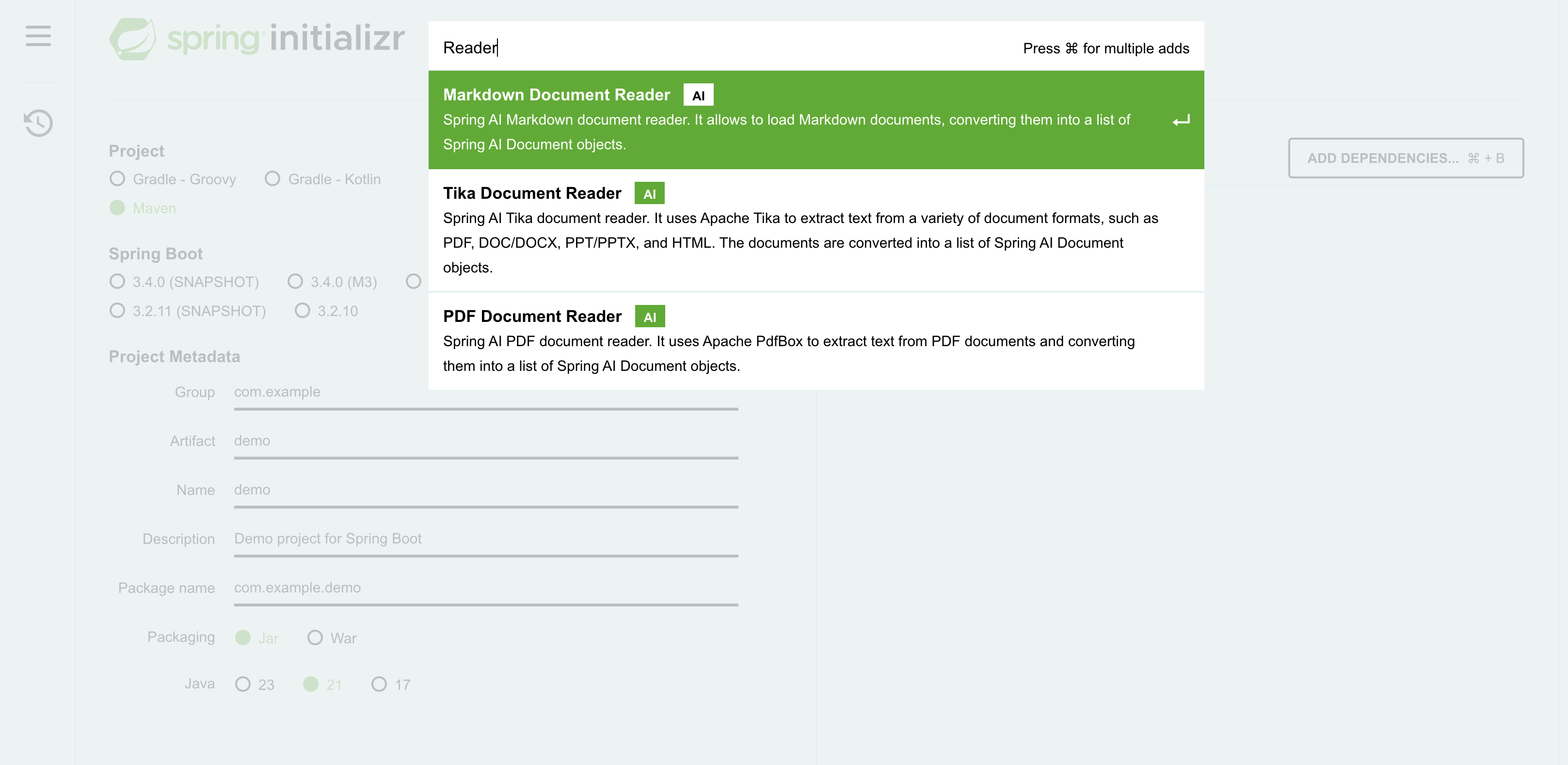
將源資料嵌入向量儲存是一項強大的功能,但在嵌入之前,如何處理不同的資料結構呢?藉助 Spring AI,你可以訪問即用型文件閱讀器,它允許你處理各種格式,包括 PDF、Markdown、Microsoft Word 和 PowerPoint 文件、HTML 等。文件閱讀器功能確保你可以處理各種源格式。如果不支援特定格式,建立自己的實現也很簡單。
Spring AI 的突出特點之一是它支援嵌入上的元資料過濾,這與底層向量儲存實現無關。在典型的 RAG(檢索增強生成)應用程式中,對向量儲存執行相似性搜尋,計算查詢與資料集中每個資料點之間的距離度量(例如,餘弦相似性)。雖然這種方法對於較小的資料集可能 manageable,但隨著資料量的增長,它變得越來越具有挑戰性。為了解決這個問題,向量儲存實現了各種效能增強演算法,例如近似最近鄰 (ANN)、區域性敏感雜湊 (LSH) 或分層可導航小世界 (HNSW)。
為了進一步解決這個挑戰,一個額外的有效策略是在執行相似性搜尋之前減少要查詢的資料量。例如,如果你只對位於波士頓的客戶感興趣,則可以將資料集過濾到只包含居住在那裡的客戶。這種減少過程稱為元資料過濾。
許多向量儲存提供了自己的元資料過濾實現,每種實現都有其優點和侷限性。然而,Spring AI 提供了一個與供應商無關的解決方案,彌合了各種向量儲存之間的差距。這種能力在企業應用程式中特別有價值,因為僅憑語義可能不足夠,並且某些個人身份資訊 (PII) 資料必須從相似性搜尋中排除。透過利用元資料過濾,相似性搜尋可以僅在文件的相關子集上執行,而不是掃描整個資料集。
這是一個簡單的示例,更多詳細資訊請參見Spring AI 參考文件
public void example() {
// Assume we have a large dataset of customers.
// Embedding the data is computationally expensive
// but it is typically a one-time / ETL process
List<Document> allMyCustomers = new ArrayList<>();
allMyCustomers.add(new Document("""
{
"customerId": 12345,
"name": "John Doe",
"email": "[email protected]",
"phone": "+1234567890",
"address": "123 Main St, Boston, MA"
}
""", Map.of("city", "Boston"))); // Metadata filter!
// Add more customers...
allMyCustomers.add(...);
// Add all embedded documents and their
// associated metadata to the vector store
vectorStore.add(allMyCustomers);
// Prepare a search query, for example:
// "Which customers are named John?"
SearchRequest searchRequest =
SearchRequest.query("Which customers are named John?");
// This similarity search is computationally intensive
List<Document> results = vectorStore.similaritySearch(
searchRequest.withTopK(5)
.withSimilarityThresholdAll());
// Instead, we'll first filter by city to reduce the dataset size,
// then perform the similarity search on the filtered results
results = vectorStore.similaritySearch(
searchRequest.withTopK(5)
.withSimilarityThresholdAll()
.withFilterExpression("city == 'Boston'"));
}
Spring AI 的突出特點之一是其函式呼叫能力,它透過解決 AI 互動的最大挑戰——與你自己的 API 整合——從而簡化了企業應用中的 AI 互動!
我最近讀到 Jonathan Schneider 的一篇 LinkedIn 帖子,引起了我的注意。他寫道,函式呼叫對於檢索增強生成 (RAG) 來說,就像 IoC 對於 Java 開發一樣。IoC 允許開發人員專注於業務邏輯,而 Spring 負責物件建立和依賴項注入。以類似的方式,Spring AI 中的函式呼叫允許開發人員專注於其函式的功能,而大型語言模型 (LLM) 則負責幕後複雜的互動。
你用自然語言描述你的函式功能,Spring AI 確保 LLM 在需要時理解並執行它。這大大減少了與 AI 模型互動通常所需的樣板程式碼量,讓你能夠專注於構建功能,而不是管理 AI 過程的複雜性。
以下是Spring AI 參考文件中的一個簡單示例
@Configuration
static class Config {
@Bean
@Description("Get the current weather in location")
public Function<WeatherService.Request, WeatherService.Response> currentWeather() {
return new MockWeatherService();
}
}
public class WeatherService implements Function<Request, Response> {
public enum Unit { C, F }
public record Request(String location, Unit unit) {}
public record Response(double temp, Unit unit) {}
public Response apply(Request request) {
// Logic goes here!
}
}
目前沒有 AI 模型能夠為特定位置提供即時天氣資料。因此,LLM 可能會回答它不知道答案——或者更糟的是,它可能會返回一個幻覺響應。
然而,透過註冊如上所示的函式,Spring AI 允許 LLM 從 `@Description` 註解推斷該函式可以提供即時天氣資料。然後,LLM 可以根據使用者的輸入,以正確的格式構建 WeatherService.Request 的請求。例如,如果使用者詢問“波士頓天氣如何?”,LLM 將自動使用位置和單位填充 `Request` 物件,要求 Spring AI 呼叫該函式,從 `WeatherService` 檢索實際天氣資料,然後根據該資料為使用者格式化一個易於閱讀的響應。
以下是呼叫流程的分步說明
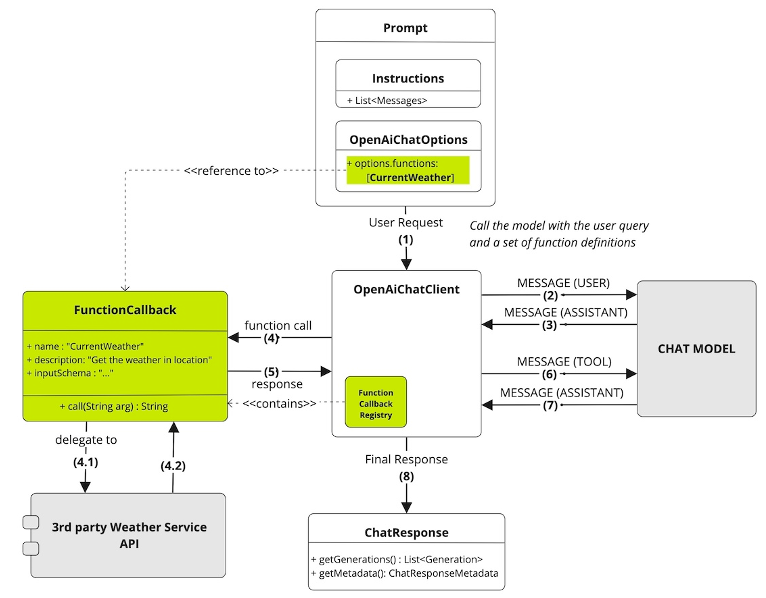
向量儲存透過將你的資料嵌入到 LLM 可以理解的格式中來預處理資料,而函式呼叫則使 LLM 能夠即時與你現有的事務性 API 互動,從而根據需要生成有意義的響應。
Spring AI 引入了 Advisors,這是一種在 AI 應用程式中處理橫切關注點的強大機制。如果你熟悉面向切面程式設計 (AOP) 攔截器或Spring MVC 攔截器,這個概念是相似的。然而,考慮到並非所有開發人員都熟悉這些術語,Spring AI 團隊選擇使用“Advisor”來強調其目的——增強請求/響應提示流——而不是其操作的技術細節,這涉及攔截請求/響應和應用過濾器。Advisors 簡化了日誌記錄、訊息轉換和聊天記憶體管理等任務的管理,同時保持你的應用程式程式碼整潔。
透過解除安裝這些例行任務,Advisors 確保你的應用程式保持專注於業務邏輯,而基本的 AI 相關操作在後臺無縫執行。這種方法保持了程式碼庫的清晰性,同時有效地解決了必要的運營問題。
以下是一個簡單的示例
this.chatClient = builder
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
new SimpleLoggerAdvisor())
.build();
此聊天客戶端集成了兩個 Advisor:一個記憶體 Advisor,用於將以前的使用者提示附加到當前訊息以提供上下文和連續性;一個日誌記錄 Advisor,用於捕獲傳送到 LLM 和從 LLM 收到的請求和響應,並將其輸出到應用程式的日誌中,以實現有效的故障排除。
在使用生成式 AI 模型時經常出現的一個挑戰是,每個模型都有其自身的怪癖。例如,要求大型語言模型提供結構化響應(例如 JSON)並不像看起來那麼簡單。LLM 經過訓練可以生成對話文字,它們通常喜歡以更像人類的方式“聊天”。這可能導致不可預測或過於冗長的輸出,這在你期望機器可讀格式時並不理想。
Spring AI 為你抽象了這些細微差別。它透過根據所使用的特定 LLM 附加適當的使用者提示或指令來自動處理這些變化。因此,無論你使用的是 OpenAI 的 GPT4-o、Anthropic 的 Claude 還是不同的 LLM,Spring AI 都能確保你收到所需結構的響應。此功能消除了開發人員試錯提示工程的需要,讓你能夠專注於利用 AI,而不是與它的怪癖作鬥爭。
這是 Spring AI 的 `BeanOutputConverter` 實現的一個示例,旨在從 LLM 中檢索 JSON 格式的響應,該響應遵循給定資料類的模式。請注意,要達到所需結果,對 LLM 的提示需要多麼詳細和具體
@Override
public String getFormat() {
String template = """
Your response should be in JSON format.
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.
Do not include markdown code blocks in your response.
Remove the ```json markdown from the output.
Here is the JSON Schema instance your output must adhere to:
```%s```
""";
return String.format(template, this.jsonSchema);
}
Spring AI 完成了繁重的工作,所以你無需親自去做。
可觀測性在任何企業應用程式中都至關重要,而用生成式 AI 增強的應用程式也不例外。Spring AI 提供內建可觀測性功能,可無縫監控 AI 服務的健康狀況和效能。這包括全面的指標、跟蹤和日誌記錄,為你的生成式 AI 應用程式提供端到端的可視性。這不僅適用於聊天模型,還適用於整個堆疊,包括嵌入模型和向量資料庫。這種能力再次突出了 Spring 這種整合解決方案的強大之處,因為可觀測性功能由Micrometer啟用,就像其他 Spring 專案一樣
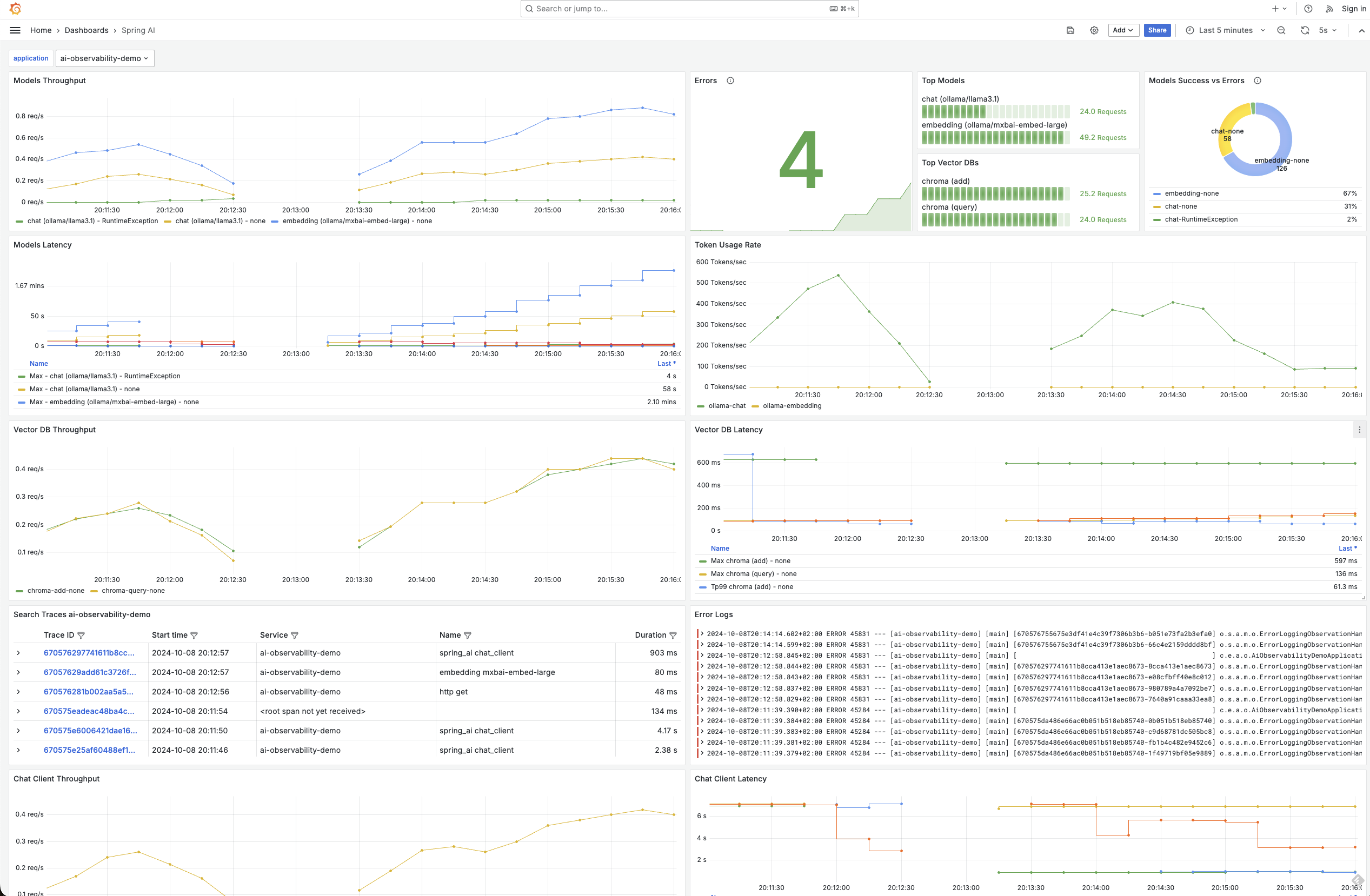
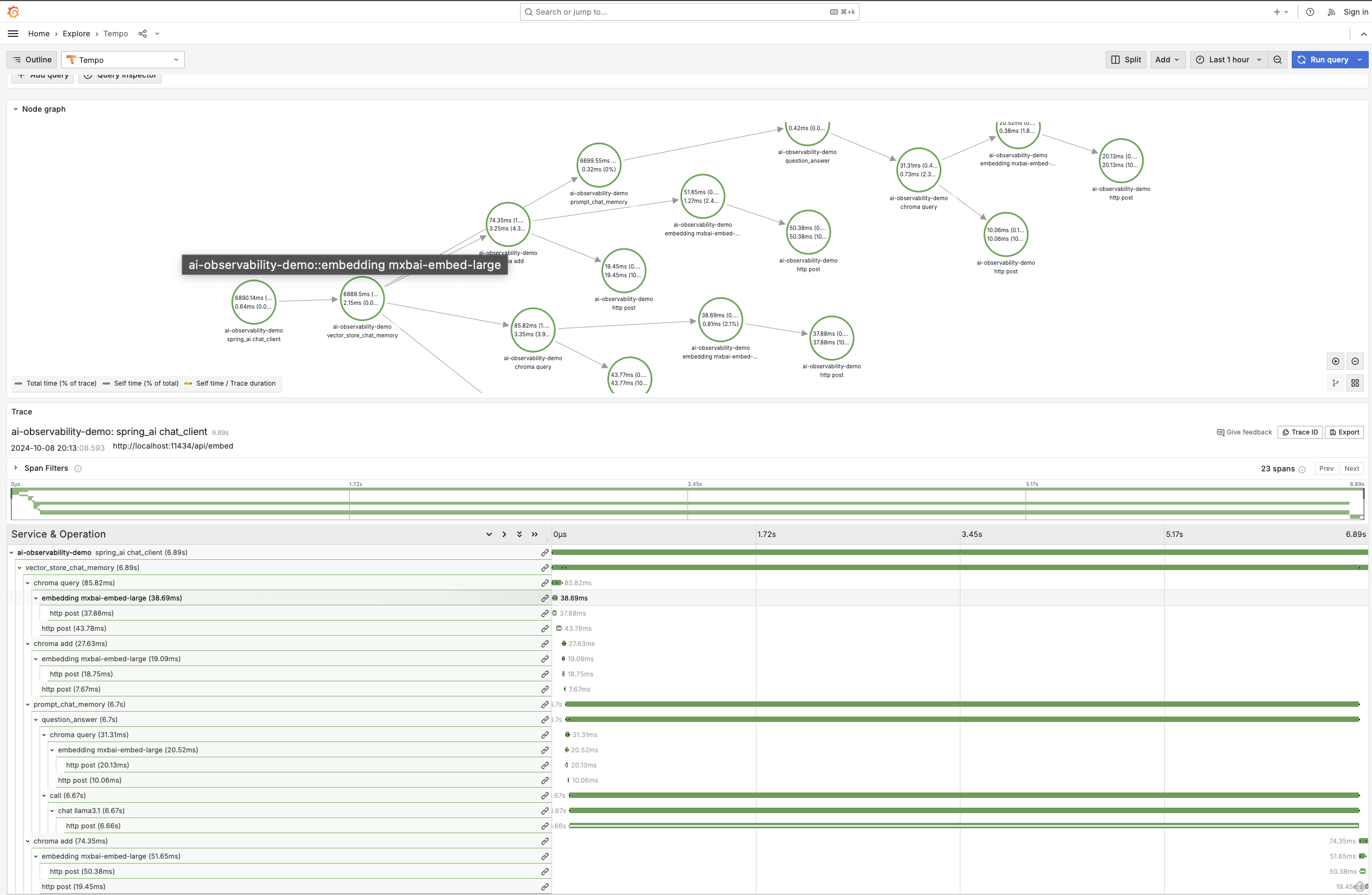
透過 Spring AI,你可以深入瞭解關鍵指標,例如令牌使用率,這對於管理與根據處理的令牌數量收費的模型進行互動時的成本至關重要。此外,你還可以監控向量儲存延遲、錯誤率,甚至跟蹤請求如何流經你的 AI 增強服務。這種級別的可觀測性確保你可以快速識別效能瓶頸或潛在問題,然後在它們影響你的應用程式之前,就像你習慣於處理其他基於 Spring 的服務一樣。
使用 Spring AI 的另一個顯著優勢是,你可以輕鬆地在不同的 LLM 提供商之間進行 A/B 測試。為了在成本和響應質量之間取得最佳平衡,能夠比較多個模型是無價的。
藉助 Spring AI,你只需替換 Spring Boot Starter 依賴項並更改屬性檔案中的幾行程式碼,即可輕鬆地在各種 LLM 之間切換。這種直接的方法使你能夠評估不同模型的效能,而無需進行大量的重新配置或編碼開銷。無論你是在評估準確性、響應時間還是成本效率,Spring AI 都提供了工具來無縫地促進這些比較。
透過將 A/B 測試直接整合到你的工作流中,你可以就哪個 LLM 提供商最適合你的應用程式需求做出資料驅動的決策。此功能不僅增強了你的 AI 實現的整體有效性,還允許隨著生成式 AI 領域中新模型和功能的出現進行持續最佳化。
Spring AI 專門旨在為 Java 開發人員提供一種無縫高效的方式,將 AI 整合到其應用程式中。這不僅僅是新增 AI 功能,更是以一種自然地融入現有系統的方式進行。將生成式 AI 應用於應用程式主要是一個整合挑戰,而這正是 Spring 框架的優勢所在。Spring AI 是 Spring 生態系統的自然延伸,旨在輕鬆處理企業應用程式整合的複雜性。
如果你的目標是使用生成模型、函式呼叫和向量嵌入來增強企業應用程式,Spring AI 是理想的選擇。它與 Spring 生態系統的深度整合,以及對廣泛的大型語言模型和向量儲存的訪問,使其在 AI 開發中既強大又簡單。它非常適合將 AI 與現有業務邏輯相結合,消除了管理多步工作流或鏈式模型的複雜性。
總而言之,Spring AI 的一些突出優勢是
無縫整合:輕鬆將 AI 功能嵌入現有 Spring 應用程式中。
為 RAG 而生:簡化資料嵌入和執行相似性搜尋的過程,同時支援強大的元資料過濾器。
函式呼叫:實現與事務性 API 的即時互動。
Advisors: 使用內建的 Advisor 處理橫切關注點,或在需要時編寫自己的 Advisor。
供應商無關:利用各種向量儲存和 LLM 提供商,而不會被鎖定在特定解決方案中,為你的資料和模型管理提供靈活性。
A/B 測試:輕鬆進行 A/B 測試以最佳化 AI 效能。
內建可觀測性:訪問監控、日誌記錄和跟蹤功能,以提高透明度。
透過選擇 Spring AI,你的企業應用程式將獲得先進的 AI 功能,從而推動創新並增強使用者體驗。