
領先一步
VMware 提供培訓和認證,助您加速進步。
瞭解更多目錄
Micrometer 是一個“維度優先”的指標收集門面,其目的是允許您使用供應商中立的 API 來計時、計數和測量您的程式碼。透過類路徑和配置,您可以選擇一個或多個監控系統來匯出您的指標資料。把它想象成 SLF4J,但用於指標!
Micrometer 是 Spring Boot 2 的 Actuator 中包含的指標收集工具。它也已向後移植到 Spring Boot 1.5、1.4 和 1.3,只需新增另一個依賴項。
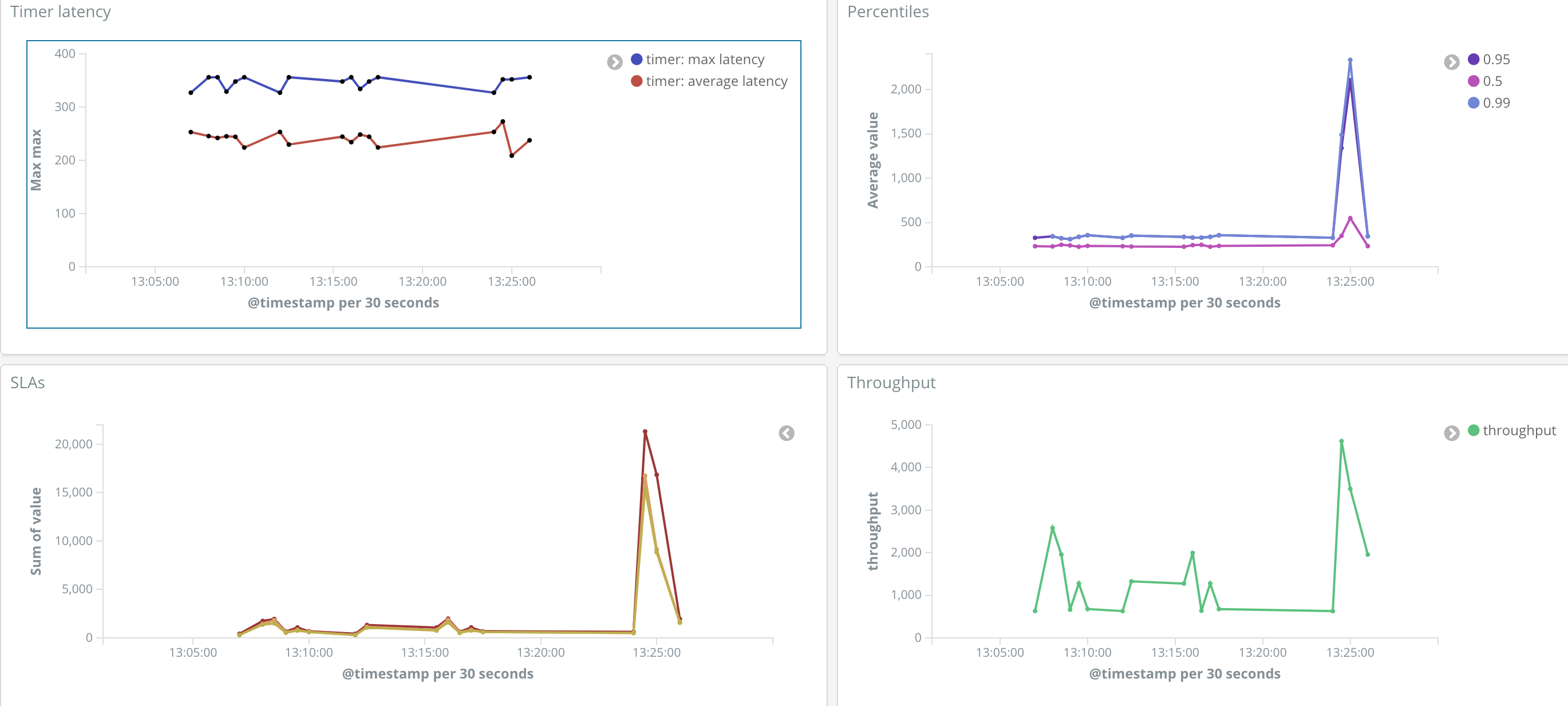
Micrometer 為 Spring Boot 1 中已有的計數器和儀表盤添加了更豐富的儀表原始型別。例如,一個 Micrometer Timer 能夠生成與吞吐量、總時間、最近樣本的最大延遲、預計算的百分位數、百分位數直方圖和 SLA 邊界計數相關的時間序列。
儘管 Micrometer 專注於維度指標,但它確實對映到分層名稱,以繼續服務於較舊的監控解決方案,如 Ganglia 或範圍較窄的工具,如 JMX。轉向 Micrometer 源於更好地服務於一波維度監控系統(例如 Prometheus、Datadog、Wavefront、SignalFx、Influx 等)的願望。Spring 的優勢之一是透過抽象實現選擇。透過與 Micrometer 整合,Spring Boot 使您能夠選擇一個或多個監控系統立即使用,並在您的需求變化時稍後改變主意,而無需重寫您的自定義指標檢測。
在選擇開發“又一個”指標收集庫之前,我們認真研究了現有或新興的維度收集器。但當我們考慮向越來越多的監控系統匯出時,名稱和資料結構的重要性變得顯而易見。Micrometer 內建了命名約定規範化、時間基本單位縮放以及對直方圖資料等專有結構表示式的支援等概念,這些對於使指標在每個目標系統中發揮作用至關重要。在此過程中,我們還添加了儀表過濾,允許您更好地控制上游依賴項的檢測。
提示
要了解有關 Micrometer 功能的更多資訊,請參閱其參考文件,特別是概念部分。
Spring Boot 2 為您自動配置了許多指標,包括
JVM,報告利用率
各種記憶體和緩衝區池
與垃圾回收相關的統計資料
執行緒利用率
載入/解除安裝的類數量
CPU 使用率
Spring MVC 和 WebFlux 請求延遲
RestTemplate 延遲
快取利用率
資料來源利用率,包括 HikariCP 連線池指標
RabbitMQ 連線工廠
檔案描述符使用情況
Logback:記錄每個級別傳送到 Logback 的事件數量
執行時間:報告執行時間的儀表盤和代表應用程式絕對啟動時間的固定儀表盤
Tomcat 使用情況
這些指標中的許多在 Spring Boot 1 中以某種形式存在,但在 Spring Boot 2 中透過更詳細的資訊和標籤得到了豐富。
Micrometer 提供了一個與供應商無關的指標收集 API(根植於 io.micrometer.core.instrument.MeterRegistry)以及各種監控系統的實現
Netflix Atlas
CloudWatch
Datadog
Ganglia
Graphite
InfluxDB
JMX
New Relic
Prometheus
SignalFx
StatsD (Etsy, dogstatsd, Telegraf 和專有格式)
Wavefront
對其他系統的支援正在進行中或計劃用於 2018 年年中釋出的 1.1.0 版本
AppOptics
Azure Application Insights
Dynatrace
Elasticsearch
StackDriver
Spring Boot 2 配置了一個複合 MeterRegistry,可以向其中新增任意數量的登錄檔實現,允許您將指標傳送到多個監控系統。透過 MeterRegistryCustomizer,您可以一次性自定義整個登錄檔集或特定的單個實現。例如,一個常見的設定是 (1) 將指標匯出到 Prometheus 和 CloudWatch,(2) 向流向兩者的指標新增一組通用標籤(例如,主機和應用程式標識標籤),以及 (3) 只允許一小部分指標流向 CloudWatch。
我們所說的指標特指一類資訊,它允許您從整體上(跨單個應用程式的不同元件、叢集中的例項、在不同環境或區域執行的叢集等)推斷系統的效能。
值得注意的是,這排除了旨在推斷各個元件對單個請求透過一系列服務時總延遲的貢獻的資訊;這是分散式跟蹤收集器(如 Spring Cloud Sleuth、Zipkin 的 Brave 等)的職責。
分散式跟蹤系統提供有關子系統延遲的詳細資訊,但通常為了擴充套件而進行降取樣(例如,Spring Cloud Sleuth 預設傳送 10% 的樣本)。指標資料通常是預先聚合的,因此自然缺乏關聯資訊,但也不會被降取樣。因此,對於一分鐘間隔內 100,000 個請求的系列,其中涉及與服務 A 的互動,並且根據輸入,可能涉及與服務 B 的互動
指標資料會告訴您,總體而言,服務 A 的觀察吞吐量為 10 萬個請求,服務 B 的觀察吞吐量為 6 萬個請求。此外,在這一分鐘內,服務 A 的最大總體平均延遲為 100 毫秒,服務 B 的最大總體平均延遲為 50 毫秒。它還將提供該時期內最大延遲和其他分佈統計資訊。
分散式跟蹤系統會告訴您,對於特定請求(而不是所有請求,因為請記住正在進行降取樣),服務 A 花費了 50 毫秒,服務 B 花費了 90 毫秒。
您可能會合理地從指標資料中推斷,最壞情況使用者體驗中大約一半的時間花在 A 和 B 中,但您不能確定,因為您正在檢視聚合資料,並且在最壞情況下,全部 100 毫秒都花在服務 A 中,並且服務 B 從未被呼叫也是完全可能的。
反之,從跟蹤資料中,您無法推斷某個時間間隔內的吞吐量或最壞情況的使用者體驗。
Spring Boot 1 的指標介面本質上是分層的。這意味著釋出的指標完全由其名稱標識。因此,您可能有一個名為 jvm.memory.used 的指標。
當您檢視單個應用程式例項的指標時,這似乎是合適的。但是,如果您有 10 個例項都將 jvm.memory.used 釋出到同一個監控系統,那該怎麼辦?如果一個例項上的記憶體消耗意外飆升,我們如何區分它們?
答案通常是新增到名稱中,例如透過在名稱中新增字首或字尾。所以我們可能會將名稱更改為 ${HOST}.jvm.memory.used,其中我們將 ${HOST} 替換為主機名。在重新部署所有 10 個例項後,我們現在可以識別哪個例項處於記憶體壓力之下。在典型的分層監控系統中,我們可以透過某種方式萬用字元名稱來推斷所有例項的記憶體使用總量
*.jvm.memory.used
現在假設我們在 3 個部署區域中每個區域有 10 個應用程式例項。此外,我們希望按區域推斷應用程式的平均或最大記憶體佔用。現在,如果我們在指標名稱中新增一個額外的字首(使其看起來像 ${REGION}.${HOST}.jvm.memory.used),我們已經破壞了現有的查詢。我們可以更新查詢以推斷所有例項的記憶體使用總量
*.*.jvm.memory.used
不幸的是,這會使我們現有的基礎設施盲目,直到所有基礎設施都使用新字首重新部署。這只是分層命名方法的一個限制示例。
我們已經提到 Micrometer 是一個維度優先的指標收集器。Micrometer 中的相同指標將與標籤(又名維度)一起記錄
Gauge.builder("jvm.memory.used", ..)
.tag("host", "MYHOST")
.tag("region", "us-east-1")
.register(registry);
維度監控系統自然會聚合顯示所有標籤的 jvm.memory.used,直到您深入研究其中一個或多個標籤。維度監控系統中的查詢將首先選擇名稱 (jvm.memory.used),然後允許按標籤進行後續過濾。在我們上面的場景中,如果我們有一個基於按主機爆炸記憶體消耗的現有圖表/警報,然後稍後新增一個額外的區域標籤,基於主機的查詢將繼續不間斷地工作,因為新的注入區域的指標在您的基礎設施中推出。
儀表過濾器允許您控制儀表註冊的方式和時間以及它們發出的統計資料型別。儀表過濾器具有三個基本功能
拒絕(或接受)儀表註冊。
轉換儀表 ID(例如更改名稱、新增或刪除標籤、更改描述或基本單位)。
配置某些儀表型別的分佈統計資料(例如計時器和分佈摘要的百分位數、直方圖、SLA)。
Spring Boot 2 將一系列屬性繫結到一個開箱即用的儀表過濾器,允許您透過屬性控制指標發射。例如
management.metrics.enable.jvm=false
management.metrics.distribution.percentiles-histogram.http.server.requests=true
management.metrics.distribution.sla.http.server.requests=1ms,5ms
上述設定關閉了所有以“jvm”為字首的指標,為 Spring Boot 自動配置的 http 伺服器請求指標釋出百分位直方圖,併發送小於或等於 1 毫秒和 5 毫秒 SLA 邊界的請求計數,以便您可以準確地看到有多少請求符合您的預期。SLA 分佈配置也是使您能夠視覺化更復雜測量(如 Apdex 分數)的核心功能。
您可以完全在根目錄翻轉指標的啟用,以生成您只想要少量指標的白名單。假設您只想要 JVM 指標,而沒有其他指標
management.metrics.enable.all=false
management.metrics.enable.jvm=true
在 Spring Boot 1 中提供一個列出所有指標的單一 REST 端點是微不足道的,因為我們只有計數器和儀表盤,並且兩者都是分層的。更復雜的型別(如計時器)代表多個時間序列(它們至少包含一個計數、一個最大值和一個總和)。此外,我們的指標變成了維度化的。很快就清楚,無法將所有這些資訊輸出到一個單一的有效負載中。即使對於維度計數器,我們是否顯示每個標籤排列的聚合資料?為了簡潔起見,將其扁平化為分層名稱,這變成了這樣
http.server.requests.method.GET.response.200.uri./foo=100
http.server.requests.method.GET.response.500.uri./foo=1
http.server.requests.method.GET.response.200.uri./bar=5
http.server.requests.method.GET.response.400.uri./foo=1
# and now the aggregates...
http.server.requests.method.GET=107
http.server.requests.method.GET.response.200=105
http.server.requests.method.GET.uri./foo=101
http.server.requests.response.200.uri./foo=100
http.server.requests.response.500.uri./foo=1
http.server.requests.response.200.uri./bar=5
...
如您所見,這很快變得難以維護。例如,如果您想在 MeterRegistry 的內容上構建自定義 UI,並且您知道您的 UI 只關心按 URI 的 http 吞吐量,而不管方法、狀態等,那麼輸出可以大大 сокра減。對於這些情況,我們建議建立一個元件,該元件僅向您的 UI 提供所需資料。將 MeterRegistry 注入您的元件,並使用其 find 和 get 方法搜尋您需要公開的指標。然後以適合您使用的格式序列化它們。
Micrometer 支援可透過 slack.micrometer.io 上的 Slack、Twitter @micrometerio 和 Github 獲得。請隨時提出問題、建議或報告問題!