
領先一步
VMware 提供培訓和認證,助您加速進步。
瞭解更多我代表團隊,非常高興地宣佈 Spring Cloud Data Flow 1.0 GA 版本釋出!
注意
開始使用此新版本的一個好方法是遵循參考文件的“入門”部分。它使用在您的計算機上執行的 Data Flow 伺服器,併為每個應用程式部署一個新程序。
Spring Cloud Data Flow (SCDF) 是用於在現代執行時上編排資料微服務的服務。SCDF 允許您描述資料管道,這些管道可以由長期執行的流應用程式或短期執行的任務應用程式組成,然後將這些管道部署到您今天可能已經使用的平臺執行時,例如 Cloud Foundry、Apache YARN、Apache Mesos 和 Kubernetes。我們提供了廣泛的流和任務應用程式,因此您可以立即開始開發用於資料攝取、即時分析和資料匯入/匯出等用例的解決方案。
流使用受Unix 管道語法啟發的 DSL 定義。例如,從 http 端點攝取資料並寫入 Apache Cassandra 資料庫的流的 DSL 定義為 http | cassandra。反過來,此 DSL 的每個元素都對映到一個專注於資料處理的 Spring Boot 微服務應用程式,該應用程式使用Spring Cloud Stream 程式設計模型。此程式設計模型允許您專注於處理應用程式的輸入和輸出,而 SCDF 配置這些輸出和輸入如何對映到訊息中介軟體,這就是應用程式通訊的方式。透過 Spring Cloud Stream 中的繫結器抽象支援多個訊息代理。目前 RabbitMQ 和 Kafka 可用於生產。Spring Cloud Stream 還支援消費者組和資料分割槽,並可以在部署流時進行配置。
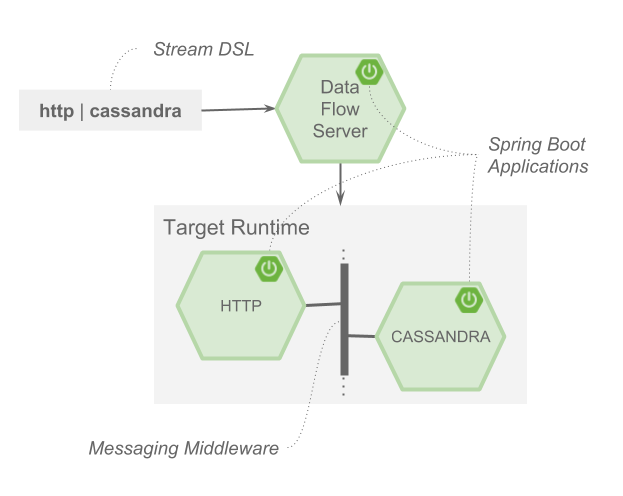
Unix 哲學“編寫只做一件事並做好它的程式”、“編寫協同工作的程式”和“編寫處理文字流的程式,因為那是一個通用介面”與 SCDF 中的微服務架構和 Spring Cloud Stream 繫結器結合在一起,這非常酷。
今天我們還宣佈釋出
Spring Cloud Data Flow 的Apache YARN Server 1.0 GA
Spring Cloud Data Flow 的Kubernetes Server 1.0 GA
Spring Cloud Data Flow 的Cloud Foundry Server 1.0 M4
對 Apache Mesos 的支援正在開發中。我們也很高興看到社群為其他執行時做出貢獻,例如OpenShift。您可以在我們的參考手冊中找到有關 SCDF 架構的更多資訊。
此版本中的顯著功能有
一種流 DSL,它將資料管道描述為單個應用程式的有向圖。
對命名目標的支援,允許您從流定義中的任何“管道”消費事件。這被稱為竊聽流。您還可以組合來自多個流的輸出。
一個部署清單,允許您定義單個應用程式的資源使用(CPU、磁碟、記憶體)以及應用程式例項計數和如何分割槽資料。您還可以在部署時傳遞任意應用程式屬性。
支援將應用程式打包為 Spring Boot uber-jar 或 Docker 映象。
支援使用 Spring Cloud Stream 部署資料微服務,用於處理無界資料量的長期執行的流應用程式,以及使用 Spring Cloud Task 部署處理有限資料集然後終止的應用程式。反過來,這些都建立在 Spring Boot 之上。
一個帶有 tab 補全功能的 shell 應用程式,用於建立、部署和監控流和任務。
一個 HTML5 儀表板,允許您建立、部署和監控已部署的流和任務。
Flo for Spring Cloud Data Flow:一個流定義的視覺化設計器,它還支援一個可指令碼化的轉換處理器,接受 Ruby、Groovy、Python 或 Javascript 程式碼用於執行時計算邏輯。
支援基本的 HTTP 和 OAuth 2.0 認證。
使用 Field Value 和 Aggregate Counters 進行“NoSql”風格的即時分析,伺服器上帶有 HTTP 端點以訪問計數器值。計數器資料由 Redis 支援。
Spring Cloud Stream 應用程式支援 RabbitMQ 和 Kafka 0.8
Spring Boot 應用程式屬性白名單為 shell/UI 提供資訊,以顯示一組首選的引導屬性,用於程式碼完成和應用程式資訊。
Spring Cloud Data Flow 已經開發了大約一年,它從之前的專案 Spring XD 演變而來,該專案也有類似的目標,即簡化流和批處理應用程式的開發。我們從那次經驗中學到了很多,Sabby Anandan 在這篇部落格文章中很好地描述了這一點。
一個主要的架構變化是使用可插拔的部署器服務提供商介面替換我們自己的應用程式執行時。雖然 Spring Cloud Data Flow 1.0 GA 中花費的大部分工程時間都花在了這種架構轉變上,但我們現在處於一個非常有利的位置,可以繼續在此基礎上新增更高層次的價值,而不必花費時間開發核心執行時功能。以下是團隊集體思考的一些想法
透過將流或任務應用程式的元件視為“普通應用程式”,我們可以利用許多其他 Spring Cloud 專案,例如 Spring Cloud Sleuth 來收集分散式應用程式中的響應時間。
與Spinnaker整合以處理應用程式的持續部署/升級職責,因為 Spinnaker 將“應用程式”作為其基本單位,並且可以使用響應時間等資料來做出自動化決策,以升級到應用程式的新版本。
多語言部署,我們希望部署更多非 Java Spring Boot 應用程式。我們將首先考慮部署 Python 應用程式,因為許多資料科學團隊使用 Python 開發需要即時評估的模型。
從 Spring XD 中帶回 Task DSL 和 UI Designer。
由於 Spring Cloud Data Flow 與 Spring Cloud Stream 和 Spring Cloud Task 的釋出生命週期解耦,因此這些專案釋出新功能時,SCDF 可以立即使用它們。Spring Cloud Stream 中值得一提的一些激動人心的功能包括對 Project Reactor 和 Kafka Streams API 的支援,以及對 Kafka 0.9、Google Cloud Pub/Sub、Azure Event Hubs 和 JMS 的繫結支援。對於 Spring Cloud Task,計劃支援 Cloud Foundry 上的最新任務功能。有關詳細資訊,請檢視這兩個專案的路線圖
有關功能、錯誤修復和改進的完整列表,請參閱已關閉的 1.0 RELEASE GitHub 問題。
我們歡迎反饋和貢獻!如果您有任何問題、評論或建議,請透過 GitHub Issues、StackOverflow 或在 Twitter 上使用 #SpringCloudDataFlow 標籤告訴我們。
SpringOne Platform 即將到來。除了涵蓋 Spring Cloud Data Flow 及相關專案的多個會議外,還將有一個為期兩天的培訓課程。整個 Spring Cloud Data Flow 團隊都將在那裡,期待在那裡見到您!