
領先一步
VMware 提供培訓和認證,助您加速進步。
瞭解更多Spring AI 現在支援 NVIDIA 的大型語言模型 API,可與各種 模型整合。透過利用 NVIDIA 的 OpenAI 相容 API,Spring AI 允許開發人員透過熟悉的 Spring AI API 使用 NVIDIA 的 LLM。
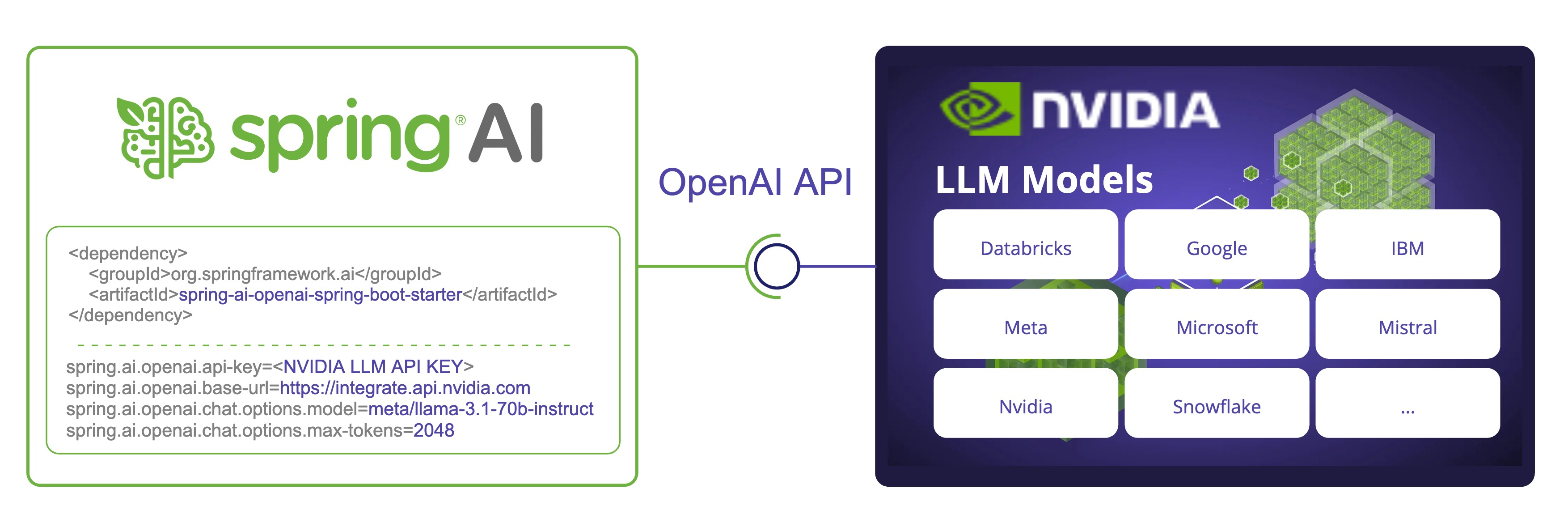
我們將探討如何配置和使用 Spring AI OpenAI 聊天客戶端連線到 NVIDIA LLM API。
meta/llama-3.1-70b-instruct。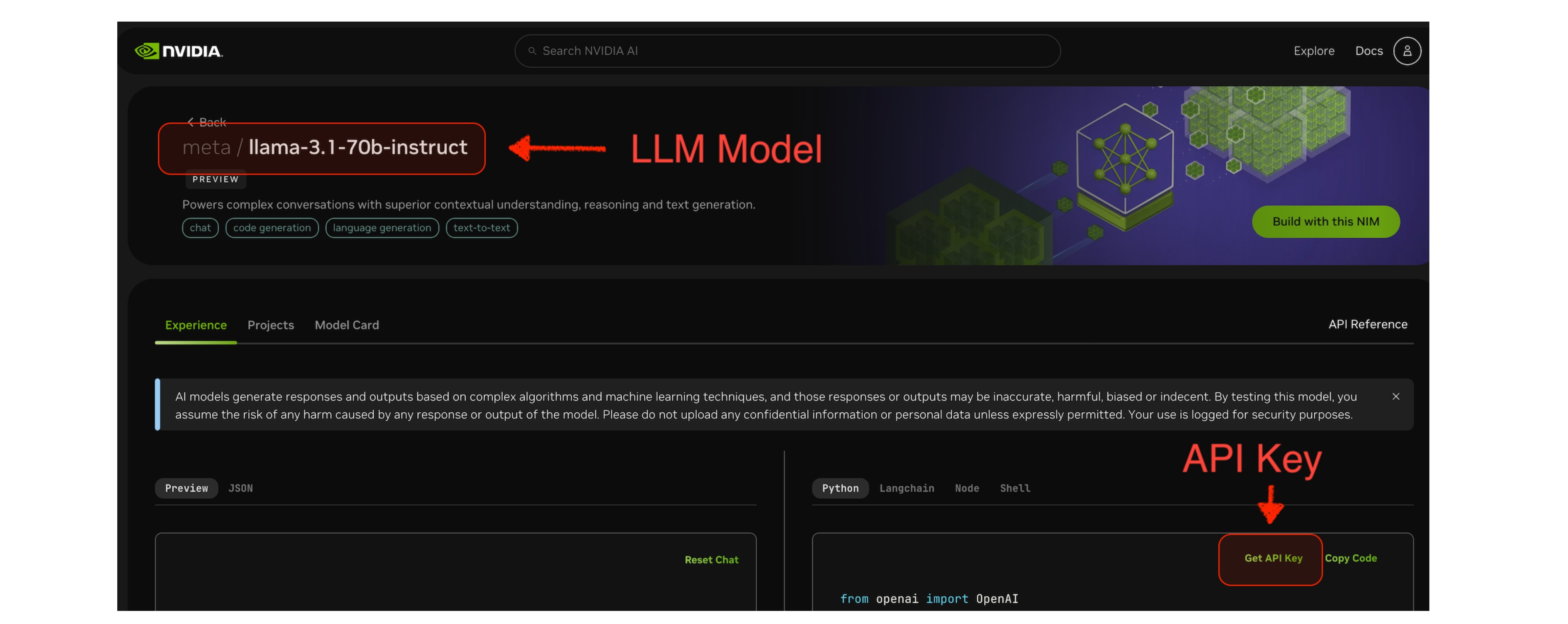
要開始,請將 Spring AI OpenAI starter 新增到您的專案中。對於 Maven,請將此新增到您的 pom.xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
對於 Gradle,請將此新增到您的 build.gradle
gradleCopydependencies {
implementation 'org.springframework.ai:spring-ai-openai-spring-boot-starter'
}
請確保您已新增 Spring Milestone 和 Snapshot 倉庫,並新增 Spring AI BOM。
要使用 Spring AI 的 NVIDIA LLM API,我們需要配置 OpenAI 客戶端以指向 NVIDIA LLM API 端點並使用 NVIDIA 特定的模型。
將以下環境變數新增到您的專案中
export SPRING_AI_OPENAI_API_KEY=<NVIDIA_API_KEY>
export SPRING_AI_OPENAI_BASE_URL=https://integrate.api.nvidia.com
export SPRING_AI_OPENAI_CHAT_OPTIONS_MODEL=meta/llama-3.1-70b-instruct
export SPRING_AI_OPENAI_EMBEDDING_ENABLED=false
export SPRING_AI_OPENAI_CHAT_OPTIONS_MAX_TOKENS=2048
或者,您可以將它們新增到您的 application.properties 檔案中
spring.ai.openai.api-key=<NVIDIA_API_KEY>
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.options.model=meta/llama-3.1-70b-instruct
# The NVIDIA LLM API doesn't support embeddings.
spring.ai.openai.embedding.enabled=false
# The NVIDIA LLM API requires this parameter to be set explicitly or error will be thrown.
spring.ai.openai.chat.options.max-tokens=2048
關鍵點
api-key 設定為您的 NVIDIA API 金鑰。base-url 設定為 NVIDIA 的 LLM API 端點:https://integrate.api.nvidia.commodel 設定為 NVIDIA LLM API 上可用的模型之一。max-tokens,否則將丟擲伺服器錯誤。embedding.enabled=false。有關完整 配置屬性 列表,請檢視參考文件。
現在我們已經配置了 Spring AI 使用 NVIDIA LLM API,讓我們來看一個在您的應用程式中使用它的簡單示例。
@RestController
public class ChatController {
private final ChatClient chatClient;
@Autowired
public ChatController(ChatClient.Builder builder) {
this.chatClient = builder.build();
}
@GetMapping("/ai/generate")
public String generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return chatClient.prompt().user(message).call().content();
}
@GetMapping("/ai/generateStream")
public Flux<String> generateStream(
@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return chatClient.prompt().user(message).stream().content();
}
}
在 ChatController.java 示例中,我們建立了一個簡單的 REST 控制器,其中包含兩個端點
/ai/generate:為給定的提示生成單個響應。/ai/generateStream:流式傳輸響應,這對於較長的輸出或即時互動非常有用。NVIDIA LLM API 端點在選擇支援工具/函式的模型之一時,支援工具/函式呼叫。
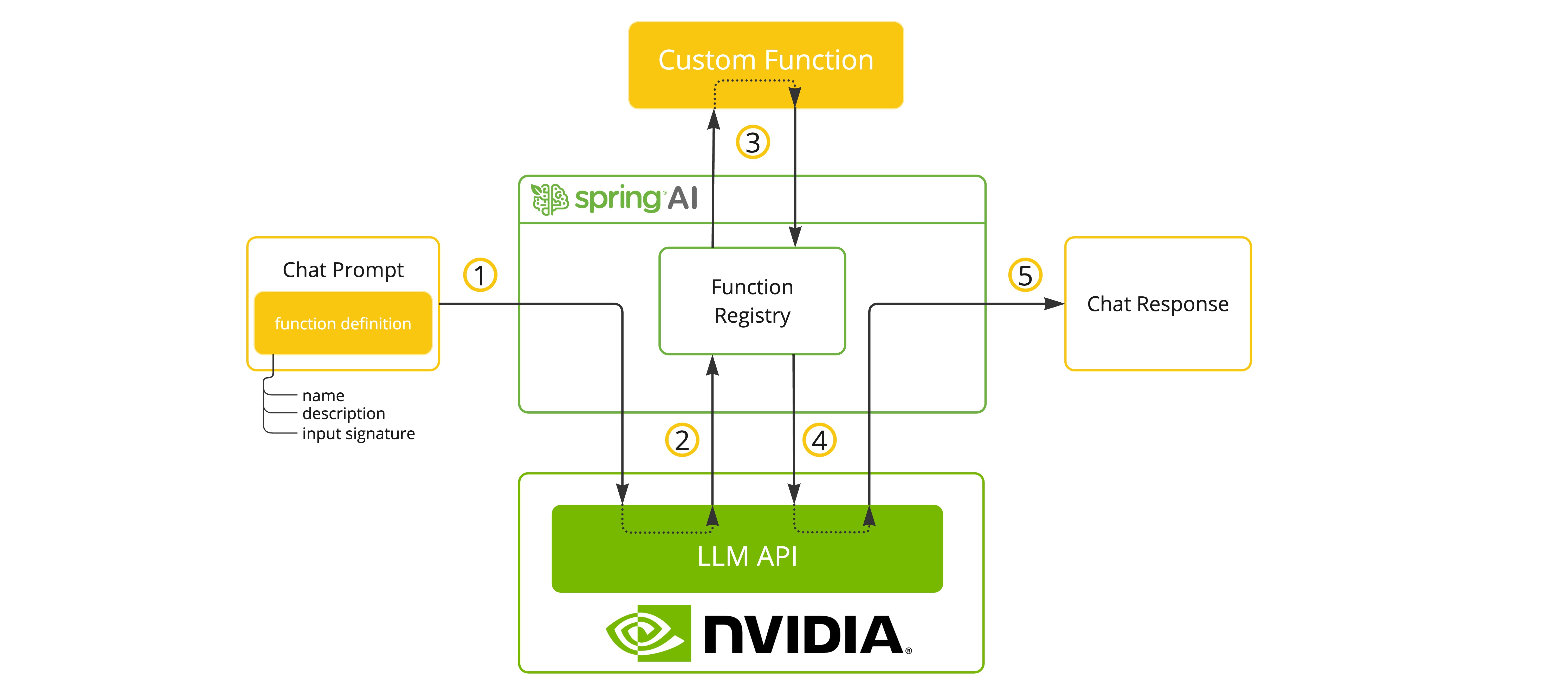
您可以將自定義 Java 函式註冊到 ChatModel,然後由提供的 LLM 模型智慧地選擇輸出一個 JSON 物件,其中包含呼叫一個或多個已註冊函式的引數。這是一種將 LLM 功能與外部工具和 API 連線的強大技術。
有關 SpringAI/OpenAI 函式呼叫 支援的更多資訊。
以下是使用 Spring AI 進行工具/函式呼叫的簡單示例
@SpringBootApplication
public class NvidiaLlmApplication {
public static void main(String[] args) {
SpringApplication.run(NvidiaLlmApplication.class, args);
}
@Bean
CommandLineRunner runner(ChatClient.Builder chatClientBuilder) {
return args -> {
var chatClient = chatClientBuilder.build();
var response = chatClient.prompt()
.user("What is the weather in Amsterdam and Paris?")
.functions("weatherFunction") // reference by bean name.
.call()
.content();
System.out.println(response);
};
}
@Bean
@Description("Get the weather in location")
public Function<WeatherRequest, WeatherResponse> weatherFunction() {
return new MockWeatherService();
}
public static class MockWeatherService implements Function<WeatherRequest, WeatherResponse> {
public record WeatherRequest(String location, String unit) {}
public record WeatherResponse(double temp, String unit) {}
@Override
public WeatherResponse apply(WeatherRequest request) {
double temperature = request.location().contains("Amsterdam") ? 20 : 25;
return new WeatherResponse(temperature, request.unit);
}
}
}
在 NvidiaLlmApplication.java 示例中,當模型需要天氣資訊時,它將自動呼叫 weatherFunction bean,然後該 bean 可以獲取即時天氣資料。預期的響應如下所示
阿姆斯特丹目前天氣為 20 攝氏度,巴黎目前天氣為 25 攝氏度。
在使用 Spring AI 的 NVIDIA LLM API 時,請牢記以下幾點
有關更多資訊,請檢視 Spring AI 和 OpenAI 的參考文件。
將 NVIDIA LLM API 與 Spring AI 整合,為希望在其 Spring 應用程式中利用高效能 AI 模型的開發人員打開了新的可能性。透過重新利用 OpenAI 客戶端,Spring AI 可以輕鬆地在不同的 AI 提供商之間切換,讓您可以為您的特定需求選擇最佳解決方案。
在探索此整合時,請記住及時瞭解 Spring AI 和 NVIDIA LLM API 的最新文件,因為功能和模型可用性可能會隨時間演變。
我們鼓勵您嘗試不同的模型並比較它們的效能和輸出,以找到最適合您用例的解決方案。
祝您編碼愉快,盡情享受 NVIDIA LLM API 為您的人工智慧驅動的 Spring 應用程式帶來的速度和功能!