
領先一步
VMware 提供培訓和認證,助您加速進步。
瞭解更多這是一篇由Gerrit Meier撰寫的客座部落格,他來自Neo4j,負責維護Spring Data Neo4j模組。
幾周前,Spring (for) GraphQL 釋出了 1.2.0 版本,帶來了一系列新功能。其中還包括與 Spring Data 模組的更佳整合。受這些變化的啟發,我們在 Spring Data Neo4j 中增加了更多支援,以便在與 Spring GraphQL 結合使用時提供最佳體驗。本文將指導您建立一個在 Neo4j 中儲存資料並支援 GraphQL 的 Spring 應用程式。如果您只對領域部分感興趣,可以愉快地跳過下一節;)
在此示例中,我選擇深入 Fediverse。更具體地說,將 伺服器 和 使用者 放在重點。為什麼選擇這個領域,現在留給讀者在接下來的段落中發現。
資料本身與可以從 Mastodon API 中獲取的屬性一致。為了簡化資料集,資料是透過手動建立而不是獲取 所有 資料。這使得資料集更容易檢查。Cypher 匯入語句如下所示
Cypher 匯入
CREATE (s1:Server {
uri:'mastodon.social', title:'Mastodon', registrations:true,
short_description:'The original server operated by the Mastodon gGmbH non-profit'})
CREATE (meistermeier:Account {id:'106403780371229004', username:'meistermeier', display_name:'Gerrit Meier'})
CREATE (rotnroll666:Account {id:'109258442039743198', username:'rotnroll666', display_name:'Michael Simons'})
CREATE
(meistermeier)-[:REGISTERED_ON]->(s1),
(rotnroll666)-[:REGISTERED_ON]->(s1)
CREATE (s2:Server {
uri:'chaos.social', title:'chaos.social', registrations:false,
short_description:'chaos.social – a Fediverse instance for & by the Chaos community'})
CREATE (odrotbohm:Account {id:'108194553063501090', username:'odrotbohm', display_name:'Oliver Drotbohm'})
CREATE
(odrotbohm)-[:REGISTERED_ON]->(s2)
CREATE
(odrotbohm)-[:FOLLOWS]->(rotnroll666),
(odrotbohm)-[:FOLLOWS]->(meistermeier),
(meistermeier)-[:FOLLOWS]->(rotnroll666),
(meistermeier)-[:FOLLOWS]->(odrotbohm),
(rotnroll666)-[:FOLLOWS]->(meistermeier),
(rotnroll666)-[:FOLLOWS]->(odrotbohm)
CREATE
(s1)-[:CONNECTED_TO]->(s2)
執行語句後,圖形成此形狀。
資料集的圖檢視

值得注意的是,即使所有使用者都關注彼此,Mastodon 伺服器也只以一個方向連線。chaos.social 伺服器上的使用者無法搜尋或瀏覽 mastodon.social 上的時間線。
免責宣告:在此示例中,伺服器的聯合使用了非雙向關係。
要跟進示例,您應該使用以下最低版本
最好訪問 https://start.spring.io 並使用 Spring Data Neo4j 和 Spring GraphQL 依賴項建立一個新專案。如果您有點懶,也可以從此 連結 下載空的專案。
要 100% 跟隨示例,您需要在系統中安裝 Docker。如果您沒有此選項或不想使用 Docker,可以使用 Neo4j Desktop 或純 Neo4j Server 偽影進行本地部署,或作為託管選項 Neo4j Aura 或 空的 Neo4j Sandbox。稍後會有關於如何連線到手動啟動的例項的說明。企業版不是必需的,社群版一切都能正常工作。
在此示例中,大部分配置工作將由 Spring Boot 自動配置完成。無需手動設定 bean。有關幕後發生情況的更多資訊,請參閱 Spring for GraphQL 文件。稍後將引用文件的特定部分。
首先要做的就是對領域類進行建模。如匯入中所示,只有 Servers 和 Accounts。
賬戶領域類
@Node
public class Account {
@Id String id;
String username;
@Property("display_name") String displayName;
@Relationship("REGISTERED_ON") Server server;
@Relationship("FOLLOWS") List<Account> following;
// constructor, etc.
}
可以合理地假設,ID 是(伺服器)唯一的。
Server 中的幾行中,使用 @Property 將資料庫欄位 display_name 對映到 Java 實體中的駝峰式命名 displayName。伺服器領域類
@Node
public class Server {
@Id String uri;
String title;
@Property("registrations") Boolean registrationsAllowed;
@Property("short_description") String shortDescription;
@Relationship("CONNECTED_TO") List<Server> connectedServers;
// constructor, etc.
}
有了這些實體類,就可以建立 AccountRepository。
賬戶儲存庫
@GraphQlRepository
public interface AccountRepository extends Neo4jRepository<Account, String> { }
有關為何使用此註解的詳細資訊稍後將提供。此處包含介面的完整性。
要連線到 Neo4j 例項,需要在 application.properties 檔案中新增連線引數。
spring.neo4j.uri=neo4j://:7687
spring.neo4j.authentication.username=neo4j
spring.neo4j.authentication.password=verysecret
如果尚未完成,可以啟動資料庫並執行上面的 Cypher 語句來設定資料。在本文的後續部分,將使用 Neo4j-Migrations 來確保資料庫始終處於所需狀態。
在研究 Spring Data 和 Spring for GraphQL 的整合功能之前,應用程式將使用帶有 @Controller 樣板批註的類進行設定。該控制器將由 Spring for GraphQL 註冊為 accounts 查詢的 DataFetcher。
@Controller
class AccountController {
private final AccountRepository repository;
AccountController(AccountRepository repository) {
this.repository = repository;
}
@QueryMapping
List<Account> accounts() {
return repository.findAll();
}
}
定義一個 GraphQL schema,該 schema 不僅定義了我們的實體,還定義了與控制器中的方法名(accounts)同名的查詢。
type Query {
accounts: [Account]!
}
type Account {
id: ID!
username: String!
displayName: String!
server: Server!
following: [Account]
lastMessage: String!
}
type Server {
uri: ID!
title: String!
shortDescription: String!
connectedServers: [Server]
}
此外,為了方便地瀏覽 GraphQL 資料,應在 application.properties 中啟用 GraphiQL。這是開發時的一個有用工具。通常應停用此設定以用於生產部署。
spring.graphql.graphiql.enabled=true
如果一切都已按照上述描述設定好,就可以使用 ./mvnw spring-boot:run 啟動應用程式。訪問 https://:8080/graphiql?path=/graphql 將會顯示 GraphiQL 瀏覽器。
在 GraphiQL 中查詢
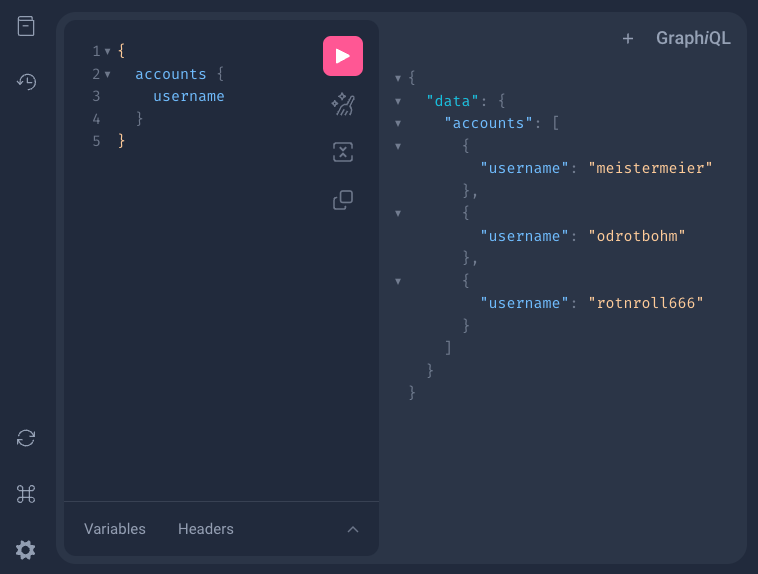
為了驗證 accounts 方法是否正常工作,嚮應用程式傳送一個 GraphQL 請求。
第一個 GraphQL 請求
{
accounts {
username
}
}
並且預期的答案從伺服器返回。
GraphQL 響應
{
"data": {
"accounts": [
{
"username": "meistermeier"
},
{
"username": "rotnroll666"
},
{
"username": "odrotbohm"
}
]
}
}
當然,控制器中的方法可以透過新增引數來調整,使用 @Argument 來處理引數,或者獲取請求的欄位(此處為 accounts.username)以減少透過網路傳輸的資料量。在前面的示例中,儲存庫將獲取給定領域實體的所有屬性,包括所有關係。這些資料將在很大程度上被丟棄,以便只向用戶返回 username。
此示例應能讓您對 Annotated Controllers 的功能有一個初步瞭解。透過新增 Spring Data Neo4j 的查詢生成和對映功能,就建立了一個(簡單的)GraphQL 應用程式。
但此時,這兩個庫似乎在這個應用程式中並行存在,而不是真正整合。SDN 和 Spring for GraphQL 如何才能真正結合起來?
作為第一步,可以刪除 AccountController 中的 accounts 方法。重新啟動應用程式並使用上面的請求再次查詢它,仍然會得到相同的結果。
這樣做是因為 Spring for GraphQL 識別出 GraphQL schema 中的結果型別(Account 的陣列)。它會掃描符合條件的 Spring Data 儲存庫,這些儲存庫必須擴充套件 QueryByExampleExecutor 或 QuerydslPredicateExecutor(在此部落格文章中未包含)。在此示例中,AccountRepository 已被隱式標記為 QueryByExampleExecutor,因為它擴充套件了 Neo4jRespository,而後者已經定義了執行器。@GraphQlRepository 註解使 Spring for GraphQL 知道該儲存庫可以並且應該用於查詢(如果可能)。
在不更改實際程式碼的情況下,可以在 schema 中定義第二個查詢欄位。這次應該按使用者名稱過濾結果。乍一看,使用者名稱看起來是唯一的,但在 Fediverse 中,這隻對給定的例項有效。多個例項可能具有相同的使用者名稱。為了尊重這種行為,查詢應該能夠返回一個 Accounts 陣列。
關於 query by example (Spring Data commons) 的文件提供了關於此機制內部工作原理的更多詳細資訊。
更新的查詢型別
type Query {
account(username: String!): [Account]!
重新啟動應用程式後,現在可以互動式地將使用者名稱新增為查詢的引數。
查詢具有相同使用者名稱的賬戶陣列
{
account(username: "meistermeier") {
username
following {
username
server {
uri
}
}
}
}
顯然,只有 Account 具有此使用者名稱。
按使用者名稱查詢的響應
{
"data": {
"account": [
{
"username": "meistermeier",
"following": [
{
"username": "rotnroll666",
"server": {
"uri": "mastodon.social"
}
},
{
"username": "odrotbohm",
"server": {
"uri": "chaos.social"
}
}
]
}
]
}
}
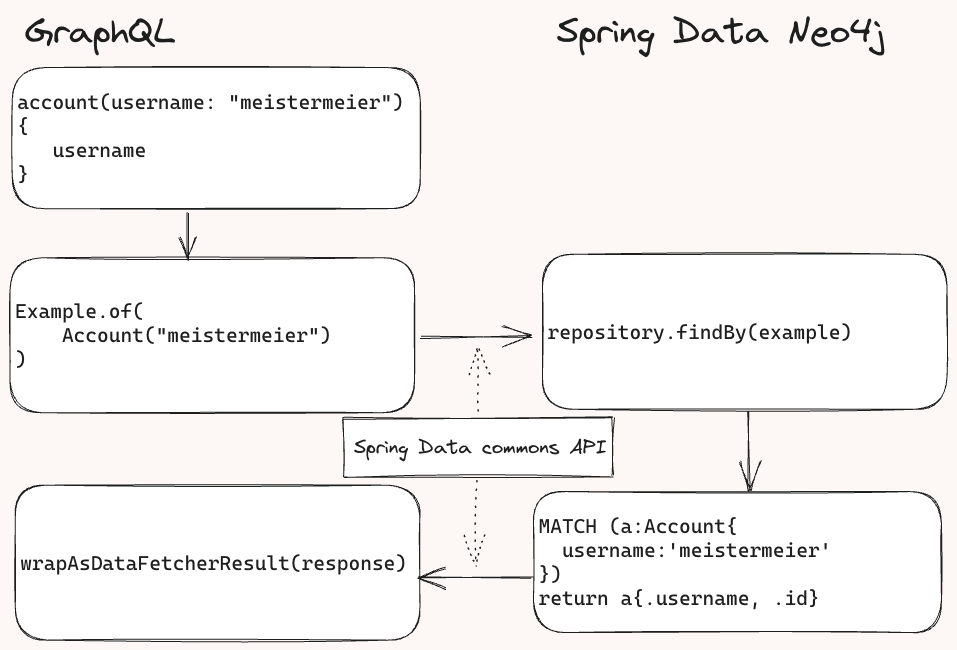
在後臺,Spring for GraphQL 將欄位作為引數新增到傳遞給儲存庫的示例物件中。Spring Data Neo4j 然後檢查示例,為 Cypher 查詢建立匹配條件,執行它,並將結果傳送回 Spring GraphQL 進行進一步處理,將結果塑造成正確的響應格式。
(示意圖)API 呼叫流程
儘管示例資料集並不龐大,但通常最好具有適當的功能來分塊請求結果資料。Spring for GraphQL 使用 Cursor Connections 規範。
包含所有型別的完整 schema 規範如下所示。
帶有遊標連線的 Schema
type Query {
accountScroll(username:String, first: Int, after: String, last: Int, before:String): AccountConnection
}
type AccountConnection {
edges: [AccountEdge]!
pageInfo: PageInfo!
}
type AccountEdge {
node: Account!
cursor: String!
}
type PageInfo {
hasPreviousPage: Boolean!
hasNextPage: Boolean!
startCursor: String
endCursor: String
}
type Account {
id: ID!
username: String!
displayName: String!
server: Server!
following: [Account]
lastMessage: String!
}
type Server {
uri: ID!
title: String!
shortDescription: String!
connectedServers: [Server]
}
儘管我個人喜歡擁有一個完整的有效 schema,但也可以在定義中跳過所有遊標連線特定的部分。僅帶有 AccountConnection 定義的查詢就足以讓 Spring for GraphQL 推導並填充缺失的部分。引數的讀取方式如下:
first:要獲取的資料量(如果沒有預設值)after:資料應在之後獲取的滾動位置last:在 before 位置之前要獲取的資料量before:資料應獲取到的(不包含)滾動位置還有一個問題:結果集按什麼順序返回?在這種情況下,穩定的排序順序是必須的,否則無法保證資料庫以可預測的順序返回資料。儲存庫還需要擴充套件 QueryByExampleDataFetcher.QueryByExampleBuilderCustomizer 並實現 customize 方法。在那裡也可以為查詢新增預設限制,在本例中為 1,以演示分頁。
已新增排序順序(和限制)
@GraphQlRepository
interface AccountRepository extends Neo4jRepository<Account, String>,
QueryByExampleDataFetcher.QueryByExampleBuilderCustomizer<Account>
{
@Override
default QueryByExampleDataFetcher.Builder<Account, ?> customize(QueryByExampleDataFetcher.Builder<Account, ?> builder) {
return builder.sortBy(Sort.by("username"))
.defaultScrollSubrange(new ScrollSubrange(ScrollPosition.offset(), 1, true));
}
}
應用程式重新啟動後,現在可以呼叫第一個分頁查詢。
第一個元素的 Pagination
{
accountScroll {
edges {
node {
username
}
}
pageInfo {
hasNextPage
endCursor
}
}
}
為了獲得用於進一步互動的元資料,還請求了 pageInfo 的一部分。
第一個元素的結果
{
"data": {
"accountScroll": {
"edges": [
{
"node": {
"username": "meistermeier"
}
}
],
"pageInfo": {
"hasNextPage": true,
"endCursor": "T18x"
}
}
}
}
現在可以使用 endCursor 進行下一次互動。使用此值作為 after 的值,並將限制設定為 2 來查詢應用程式...
最後一個元素的 Pagination
{
accountScroll(after:"T18x", first: 2) {
edges {
node {
username
}
}
pageInfo {
hasNextPage
endCursor
}
}
}
...結果是最後一個(或最後幾個)元素。此外,沒有下一頁的標記(hasNextPage=false)表明分頁已到達資料集的末尾。
最後一個元素的結果
{
"data": {
"accountScroll": {
"edges": [
{
"node": {
"username": "odrotbohm"
}
},
{
"node": {
"username": "rotnroll666"
}
}
],
"pageInfo": {
"hasNextPage": false,
"endCursor": "T18z"
}
}
}
}
也可以透過使用定義的 last 和 before 引數向後滾動資料。此外,完全可以將此滾動與已知的 query by example 功能相結合,並在 GraphQL schema 中定義一個也接受 Account 欄位作為過濾條件的查詢。
帶分頁的過濾器
accountScroll(username:String, first: Int, after: String, last: Int, before:String): AccountConnection
使用 GraphQL 的一個主要優點是引入聯合資料的選項。簡而言之,這意味著應用程式資料庫中儲存的資料可以被豐富,如本例所示,可以從遠端系統/微服務/...
可以透過利用已定義的控制器來實現這種資料聯合。
用於聯合資料的 SchemaMapping
@Controller
class AccountController {
@SchemaMapping
String lastMessage(Account account) {
var id = account.getId();
String serverUri = account.getServer().getUri();
WebClient webClient = WebClient.builder()
.baseUrl("https://" + serverUri)
.build();
return webClient.get()
.uri("/api/v1/accounts/{id}/statuses?limit=1", id)
.exchangeToMono(clientResponse ->
clientResponse.statusCode().equals(HttpStatus.OK)
? clientResponse
.bodyToMono(String.class)
.map(AccountController::extractData)
: Mono.just("could not retrieve last status")
)
.block();
}
}
在 schema 中向 Account 新增 lastMessage 欄位並重新啟動應用程式,現在就有選項來查詢帶有此附加資訊的賬戶了。
帶聯合資料的查詢
{
accounts {
username
lastMessage
}
}
帶聯合資料的響應
{
"data": {
"accounts": [
{
"username": "meistermeier",
"lastMessage": "@taseroth erst einmal schauen, ob auf die Aussage auch Taten folgen ;)"
},
{
"username": "odrotbohm",
"lastMessage": "Some #jMoleculesp/#SpringCLI integration cooking to easily add the former[...]"
},
{
"username": "rotnroll666",
"lastMessage": "Werd aber das Rad im Rückwärts-Turbo schon irgendwie vermissen."
}
]
}
}
再次檢視控制器,可以清楚地看到資料檢索現在是一個瓶頸。對於每個 Account,都會發出一個接一個的請求。但是,Spring for GraphQL 有助於改善每個 Account 的順序請求情況。解決方案是在 lastMessage 欄位上使用 @BatchMapping,而不是 @SchemaMapping。
用於聯合資料的 BatchMapping
@Controller
public class AccountController {
@BatchMapping
public Flux<String> lastMessage(List<Account> accounts) {
return Flux.concat(
accounts.stream().map(account -> {
var id = account.getId();
String serverUri = account.getServer().getUri();
WebClient webClient = WebClient.builder()
.baseUrl("https://" + serverUri)
.build();
return webClient.get()
.uri("/api/v1/accounts/{id}/statuses?limit=1", id)
.exchangeToMono(clientResponse ->
clientResponse.statusCode().equals(HttpStatus.OK)
? clientResponse
.bodyToMono(String.class)
.map(AccountController::extractData)
: Mono.just("could not retrieve last status")
);
}).toList());
}
}
為了進一步改善這種情況,建議也為結果引入適當的快取。聯合資料可能不需要在每次請求時都獲取,而只在一定時間後重新整理。
Neo4j-Migrations 是一個將遷移應用於 Neo4j 的專案。為了確保資料庫中始終存在乾淨的資料狀態,提供了一個初始 Cypher 語句。其內容與本文開頭的 Cypher 程式碼片段相同。事實上,內容直接包含在此檔案中。
透過提供 Spring Boot 啟動器將 Neo4j-Migrations 放入類路徑,它將執行預設資料夾(resources/neo4j/migrations)中的所有遷移。
Neo4j-Migrations 依賴定義
<dependency>
<groupId>eu.michael-simons.neo4j</groupId>
<artifactId>neo4j-migrations-spring-boot-starter</artifactId>
<version>${neo4j-migrations.version}</version>
<scope>test</scope>
</dependency>
Spring Boot 3.1 帶來了 Testcontainers 的新功能。其中一項功能是自動設定屬性,無需定義 @DynamicPropertySource。在測試執行期間,容器啟動後,(Spring Boot 已知的)屬性將被填充。
首先,需要在 pom.xml 檔案中新增 Testcontainers Neo4j 的依賴定義。
Testcontainers 依賴定義
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>neo4j</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testcontainers</groupId>
<artifactId>junit-jupiter</artifactId>
<scope>test</scope>
</dependency>
為了使用 Testcontainers Neo4j,將建立一個容器定義介面。
容器配置
interface Neo4jContainerConfiguration {
@Container
@ServiceConnection
Neo4jContainer<?> neo4jContainer = new Neo4jContainer<>(DockerImageName.parse("neo4j:5"))
.withRandomPassword()
.withReuse(true);
}
然後可以使用 @ImportTestContainers 註解在(整合)測試類中使用它。
用 @ImportTestContainers 註解的測試
@SpringBootTest
@ImportTestcontainers(Neo4jContainerConfiguration.class)
class Neo4jGraphqlApplicationTests {
final GraphQlTester graphQlTester;
@Autowired
public Neo4jGraphqlApplicationTests(ExecutionGraphQlService graphQlService) {
this.graphQlTester = ExecutionGraphQlServiceTester.builder(graphQlService).build();
}
@Test
void resultMatchesExpectation() {
String query = "{" +
" account(username:\"meistermeier\") {" +
" displayName" +
" }" +
"}";
this.graphQlTester.document(query)
.execute()
.path("account")
.matchesJson("[{\"displayName\":\"Gerrit Meier\"}]");
}
}
為了完整性,此類還包括 GraphQlTester 和一個測試應用程式 GraphQL API 的示例。
現在也可以直接從測試資料夾執行整個應用程式並使用 Testcontainers 映象。
從測試類使用容器啟動應用程式
@TestConfiguration(proxyBeanMethods = false)
class TestNeo4jGraphqlApplication {
public static void main(String[] args) {
SpringApplication.from(Neo4jGraphqlApplication::main)
.with(TestNeo4jGraphqlApplication.class)
.run(args);
}
@Bean
@ServiceConnection
Neo4jContainer<?> neo4jContainer() {
return new Neo4jContainer<>("neo4j:5").withRandomPassword();
}
}
@ServiceConnection 註解還負責使從測試類啟動的應用程式知道容器正在執行的座標(連線字串、使用者名稱、密碼等)。
要在 IDE 外部啟動應用程式,現在也可以呼叫 ./mvnw spring-boot:test-run。如果測試資料夾中只有一個帶有 main 方法的類,它將被啟動。
與 QueryByExampleExecutor 並行,Spring Data Neo4j 模組支援 QuerydslPredicateExecutor。要使用它,儲存庫需要擴充套件 CrudRepository 而不是 Neo4jRepository,並將其宣告為給定型別的 QuerydslPredicateExecutor。新增對滾動/分頁的支援還需要新增 QuerydslDataFetcher.QuerydslBuilderCustomizer 並實現其 customize 方法。
本文介紹的整個基礎設施也適用於響應式堆疊。基本上,將所有內容都加上 Reactive... 字首(如 ReactiveQuerybyExampleExecutor)將使其成為一個響應式應用程式。
最後但並非最不重要的一點是,這裡使用的滾動機制基於 OffsetScrollPosition。還有一個 KeysetScrollPosition 可用。它利用排序屬性與定義 ID 結合使用。
@Override
default QueryByExampleDataFetcher.Builder<Account, ?> customize(QueryByExampleDataFetcher.Builder<Account, ?> builder) {
return builder.sortBy(Sort.by("username"))
.defaultScrollSubrange(new ScrollSubrange(ScrollPosition.keyset(), 1, true));
}
很高興看到 Spring Data 模組中的便捷方法不僅為使用者的用例提供了更廣泛的可訪問性,而且還被其他 Spring 專案用來減少需要編寫的程式碼量。這使得現有程式碼庫的維護量減少,並有助於關注業務問題而不是基礎設施。
這篇帖子有點長,因為我明確希望至少觸及查詢被呼叫時發生的事情的表面,而不僅僅是談論神奇的結果。
請繼續探索可能實現的功能以及應用程式對不同型別查詢的行為。在一篇博文中涵蓋所有可用主題和功能幾乎是不可能的。
祝您 GraphQL 編碼和探索愉快。您可以在 GitHub 上找到示例專案,地址為 https://github.com/meistermeier/spring-graphql-neo4j。